「robots.txtでAIクローラーを全部ブロックしたら、ChatGPTにもPerplexityにも引用されなくなった」——2026年、この失敗談を聞く機会が急増しています。逆に、AIクローラーを無制限に許可した結果、有料コンテンツが学習データに吸い上げられ、収益モデルが崩壊したケースもあります。
問題の根本は、AIクローラーの制御とAI向けの情報提供を、戦略なく場当たり的に行っていることです。2026年のサイト設計には、従来のSEO技術に加えて「AIに読まれる設計」という新しいレイヤーが必要になりました。
この記事では、llms.txt の仕様と書き方、主要AIクローラーの一覧と制御方法、そして robots.txt + llms.txt + sitemap.xml + 構造化データの4点セット設計を、実装レベルで解説します。LLMO対策の全体像やGEO施策と組み合わせることで、「AIに引用されるサイト」の技術基盤が完成します。
AIクローラーとは何か——Googlebotとの決定的な違い
AIクローラーとは、ChatGPT・Perplexity・Claude・Geminiなどの生成AIサービスがWebからコンテンツを収集するために運用するボットの総称です。 従来のGooglebotやBingbotとは、目的・挙動・制御方法の3点で根本的に異なります。
目的の違い
Googlebotの目的は「検索インデックスの構築」です。クロールしたページをインデックスに登録し、ユーザーが検索したときにランキング結果として返します。一方、AIクローラーの目的は大きく2つに分かれます。
- LLMの学習データ収集: モデルの事前学習(プレトレーニング)や微調整(ファインチューニング)に使うためにWebを大規模にクロールする。CCBot(Common Crawl)やBytespider(ByteDance)がこの用途です
- リアルタイム検索・引用: ChatGPT SearchやPerplexityのように、ユーザーの質問に答えるためにリアルタイムでWebを検索し、回答内にソースとして引用する。GPTBot(Browse時)やPerplexityBotがこの用途です
この区別が極めて重要です。用途1のクローラーをブロックしても検索露出は減りませんが、用途2のクローラーをブロックするとAI検索からの引用・流入が消えます。
挙動の違い
Googlebotはrobots.txtを厳密に遵守し、クロール頻度をSearch Consoleで調整できます。一方、AIクローラーには以下の特徴があります。
- robots.txtの遵守度はクローラーごとに異なる: GPTBotやClaudeBotはrobots.txtを尊重すると公式に宣言していますが、すべてのAIクローラーが同じ水準で遵守するわけではありません
- クロール頻度の制御手段が限定的: Search Consoleのような管理画面は存在せず、robots.txtのCrawl-delayディレクティブも対応状況がまちまちです
- JavaScriptレンダリングへの対応が不均一: 一部のAIクローラーはJSを実行せず、HTMLの静的コンテンツのみを取得します。SPAサイトはSSR/SSGが必須です
制御方法の違い
Googlebotはrobots.txt + メタタグ(noindex / nofollow)+ Search Console の3層で精密に制御できます。AIクローラーの制御手段は、現時点では以下の3つです。
- robots.txt: User-Agentを指定してDisallowまたはAllowを設定する(最も基本的)
- HTTPヘッダ:
X-Robots-Tagヘッダで個別ページ単位の制御を行う(一部クローラーが対応) - llms.txt: AIに「読んでほしいコンテンツ」を積極的に宣言する(ブロックではなくガイド)
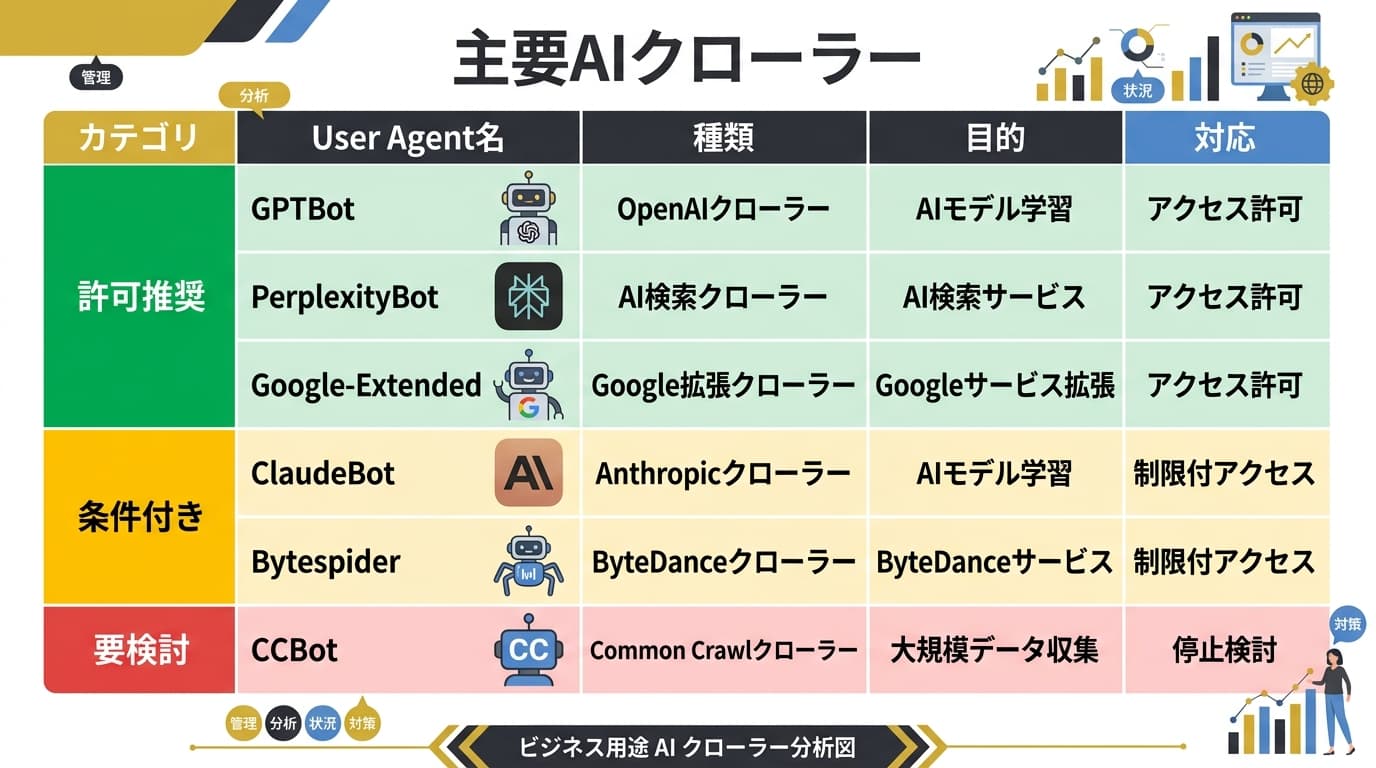
主要AIクローラー一覧と動向【2026年4月時点】
以下は、2026年4月時点で確認されている主要AIクローラーの一覧です。サイト運営者が制御判断を行うために必要な情報を整理しました。
| クローラー名 | 運営元 | User-Agent文字列 | 主な用途 | robots.txt遵守 | 推奨対応 |
|---|---|---|---|---|---|
| GPTBot | OpenAI | GPTBot | LLM学習データ収集 | 遵守(公式宣言) | 引用を望むなら許可 |
| ChatGPT-User | OpenAI | ChatGPT-User | ChatGPT Searchのリアルタイム検索 | 遵守(公式宣言) | 許可推奨(AI検索流入に直結) |
| OAI-SearchBot | OpenAI | OAI-SearchBot | SearchGPT検索専用 | 遵守(公式宣言) | 許可推奨 |
| ClaudeBot | Anthropic | ClaudeBot | Claude Web Search用 | 遵守(公式宣言) | 許可推奨 |
| anthropic-ai | Anthropic | anthropic-ai | LLM学習データ収集 | 遵守(公式宣言) | ビジネス判断 |
| PerplexityBot | Perplexity | PerplexityBot | リアルタイム検索・引用 | 遵守(公式宣言) | 許可推奨(インライン引用に直結) |
| Google-Extended | Google-Extended | Gemini/Bard学習データ | 遵守(公式宣言) | ビジネス判断 | |
| Bytespider | ByteDance | Bytespider | LLM学習データ収集 | 部分的 | ブロック推奨(学習専用・高負荷) |
| CCBot | Common Crawl | CCBot | オープンデータセット構築 | 遵守 | ブロック推奨(学習専用) |
| Applebot-Extended | Apple | Applebot-Extended | Apple Intelligence学習 | 遵守(公式宣言) | ビジネス判断 |
| cohere-ai | Cohere | cohere-ai | LLM学習データ収集 | 遵守 | ビジネス判断 |
| Amazonbot | Amazon | Amazonbot | Alexa/AI学習 | 遵守 | ビジネス判断 |
| Meta-ExternalAgent | Meta | Meta-ExternalAgent | LLM学習データ収集 | 遵守 | ビジネス判断 |
3つのカテゴリで整理する
上記のクローラーは、サイト運営者の観点から3つのカテゴリに分類できます。
カテゴリA: リアルタイム検索系(許可推奨) ChatGPT-User、OAI-SearchBot、PerplexityBot、ClaudeBot。これらをブロックすると、AI検索結果に自社コンテンツが引用されなくなります。AI検索からの流入・ブランド露出を得たいサイトは必ず許可すべきです。
カテゴリB: 学習データ収集系(ビジネス判断) GPTBot、anthropic-ai、Google-Extended、Applebot-Extended、cohere-ai、Amazonbot、Meta-ExternalAgent。自社コンテンツがAIモデルの学習に使われることを許容するかどうかの判断です。引用されるためにはモデルが自社コンテンツを「知っている」必要があるため、引用を目指すなら許可が有利ですが、有料コンテンツの保護を優先する場合はブロックが妥当です。
カテゴリC: 高負荷・学習専用系(ブロック推奨) Bytespider、CCBot。サーバー負荷が大きく、直接的な引用メリットが少ないため、多くのサイトでブロックが推奨されます。
llms.txtとは何か——仕様・目的・設置方法
llms.txtの概要
llms.txtとは、Webサイトの構造・概要・主要コンテンツをAI/LLMに対して宣言するためのテキストファイルです。 サイトルート(https://example.com/llms.txt)に設置します。
この仕様は、Jeremy Howard氏(fast.ai創設者)が2024年に提案したもので、2025年から2026年にかけて急速に普及が進んでいます。核心的なアイデアは次の通りです。
- robots.txtが「何をクロールしてはいけないか」を宣言するのに対し、llms.txtは「何を優先的に読んでほしいか」を宣言する
- AIがサイトを理解するために必要な情報(サイトの説明、主要ページ、カテゴリ構造)を、マークダウン形式で簡潔に提供する
- LLMのコンテキストウィンドウに収まるサイズ(数千トークン程度)に情報を圧縮する
llms.txtの仕様ルール
提案仕様に基づく基本ルールを整理します。
1. ファイル形式と設置場所- ファイル名:
llms.txt(小文字) - 設置場所: サイトルートディレクトリ(
/llms.txtでアクセス可能にする) - 文字コード: UTF-8
- MIME type:
text/plainまたはtext/markdown
llms.txtはMarkdown形式で記述し、以下の構造を取ります。
# サイト名
> サイトの1行説明(ブロック引用)
サイトの詳細説明(任意・複数段落可)
## セクション見出し
- [ページタイトル](URL): 説明文
- [ページタイトル](URL): 説明文
- H1見出し(#): サイト名を記述。ファイル内に1つのみ
- ブロック引用(>): サイトの簡潔な説明。1〜2文で「このサイトは何か」を宣言する
- H2見出し(##): セクション分け。「主要コンテンツ」「カテゴリ」「ドキュメント」などの分類に使う
- リストリンク(- タイトル: 説明): 各ページへのリンクとその説明。コロン(
:)の後に説明を記述する - Optionalセクション:
## Optional以下に配置したリンクは「余裕があれば参照してほしい」補足情報を示す
仕様では llms-full.txt という追加ファイルも定義されています。
llms.txt: サイトの概要と主要ページへのリンク(コンパクト版、推奨1,000〜3,000トークン)llms-full.txt: サイトの全コンテンツをマークダウン化した詳細版(数万トークン規模も可)
実務的には、まず llms.txt を作成し、必要に応じて llms-full.txt を追加する段階的アプローチが推奨されます。
llms.txt サンプルコード——中規模メディアサイト向け
以下は、月間50〜200記事程度の中規模メディアサイトを想定したllms.txtのサンプルです。実際のサイトに合わせてカスタマイズしてください。
# Agentic Base
> Agentic Baseは、AIエージェント・生成AI・Web運用の実務ノウハウを発信するビジネスメディアです。事業会社のマーケター・Web担当者・経営層を主な読者としています。
当サイトでは、AIエージェントの設計パターン、LLMO/GEO対策、Web運用自動化、AI導入のROI設計など、実務に直結するテーマを扱います。記事はすべて一次情報・実測データに基づいて執筆しています。
## 主要カテゴリ
- [AIエージェント設計](https://example.com/category/ai-agent-design): AIエージェントの設計パターン、実装手法、評価指標を解説するカテゴリ
- [マーケティング・SEO](https://example.com/category/marketing-seo): LLMO、GEO、AIO、テクニカルSEOなど検索・AI検索最適化のカテゴリ
- [Web運用](https://example.com/category/web-operations): CMS運用、コンテンツ制作フロー、アクセス解析など実務運用のカテゴリ
- [技術・設計・開発](https://example.com/category/tech-dev): RAG、MCP、n8n、Dify等の技術解説カテゴリ
## 人気記事・代表コンテンツ
- [AIエージェントとは?](https://example.com/posts/01_what-is-ai-agent): AIエージェントの定義・仕組み・活用事例を初心者向けに解説
- [LLMO対策ガイド2026年版](https://example.com/posts/78_llmo-guide-2026): AI検索で引用されるためのC-CITEモデルと30項目チェックリスト
- [GEO対策ガイド2026年版](https://example.com/posts/81_geo-optimization-guide-2026): Generative Engine Optimizationの実装手順と効果測定
- [RAG入門2026年版](https://example.com/posts/61_rag-explained-2026): Retrieval-Augmented Generationの仕組みと実装パターン
- [Claude Code完全ガイド](https://example.com/posts/56_claude-code-complete-guide): Claude Codeの使い方・設定・実務活用法
## サイト情報
- [運営者情報](https://example.com/about): サイト運営者・編集方針・連絡先
- [プライバシーポリシー](https://example.com/privacy): 個人情報の取り扱い方針
- [サイトマップ](https://example.com/sitemap.xml): 全記事のXMLサイトマップ
## Optional
- [記事一覧](https://example.com/posts): 全記事の時系列一覧
- [タグ一覧](https://example.com/tags): トピック別のタグ一覧ページサンプルの設計ポイント
このサンプルにはいくつかの意図的な設計が含まれています。
- H1直下のブロック引用で「このサイトは何か」を1文で宣言する: LLMがコンテキストの冒頭で読む情報なので、最も重要です
- カテゴリ構造を明示する: AIがサイトの全体像を把握できるようにします。記事が500本あっても、カテゴリ4〜8個で構造を圧縮できます
- 代表コンテンツを5〜10本に絞る: すべての記事を列挙するのではなく、AIに最も読んでほしい記事を厳選します。これはllms.txtのトークン数を抑えつつ、重要コンテンツの発見性を最大化する戦略です
- Optionalセクションで補足情報を分離する: 必須ではないがあれば便利な情報を明示的に分けます
- 各リンクにコロン(:)の後の説明文を付ける: 仕様に準拠した形式で、AIがリンク先の内容を事前に把握できます
robots.txtでのAIクローラー制御——実装テンプレート
robots.txtは、AIクローラー制御の最も基本的かつ効果的な手段です。以下に、前述の3カテゴリ分類に基づいた実装テンプレートを示します。
パターン1: AI検索での引用を最大化したい場合
# ===== 従来の検索エンジン =====
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# ===== カテゴリA: リアルタイム検索系(許可) =====
User-agent: ChatGPT-User
Allow: /
User-agent: OAI-SearchBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: ClaudeBot
Allow: /
# ===== カテゴリB: 学習データ収集系(許可) =====
User-agent: GPTBot
Allow: /
User-agent: anthropic-ai
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: Applebot-Extended
Allow: /
# ===== カテゴリC: 高負荷・学習専用系(ブロック) =====
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
# ===== llms.txt と Sitemap =====
Sitemap: https://example.com/sitemap.xml
パターン2: 有料コンテンツを保護しつつ無料コンテンツの引用は許可
# ===== カテゴリA: リアルタイム検索系(無料コンテンツのみ許可) =====
User-agent: ChatGPT-User
Allow: /blog/
Allow: /guides/
Disallow: /premium/
Disallow: /members/
User-agent: PerplexityBot
Allow: /blog/
Allow: /guides/
Disallow: /premium/
Disallow: /members/
User-agent: ClaudeBot
Allow: /blog/
Allow: /guides/
Disallow: /premium/
Disallow: /members/
# ===== カテゴリB・C: 学習系は全面ブロック =====
User-agent: GPTBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
Sitemap: https://example.com/sitemap.xml
パターン3: AIクローラーを全面ブロック(非推奨だが有効な場面も)
# AI クローラーをすべてブロック
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /
User-agent: OAI-SearchBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: Bytespider
Disallow: /
User-agent: CCBot
Disallow: /
Sitemap: https://example.com/sitemap.xml
パターン3は「ニュースメディアでコンテンツの無断学習を防ぎたい」「有料レポートのみを配信しており引用されること自体がビジネスリスクになる」といった限定的なケースでのみ検討してください。多くの事業会社サイトではパターン1またはパターン2が適切です。
robots.txt設定時の注意点
- User-Agentの大文字・小文字: robots.txt仕様ではUser-Agent名は大文字小文字を区別しません。ただし、公式ドキュメントに記載されている表記に合わせるのがベストプラクティスです
- 新しいAIクローラーの出現: AI業界の動きは速く、新しいクローラーが次々と登場します。四半期に1回はrobots.txtを見直し、新規クローラーへの対応を追加する運用が必要です
- Crawl-delayの対応状況:
Crawl-delayディレクティブはGooglebotが非対応で、AIクローラーも対応がまちまちです。サーバー負荷対策にはrobots.txtよりもCDNやレートリミットの方が確実です
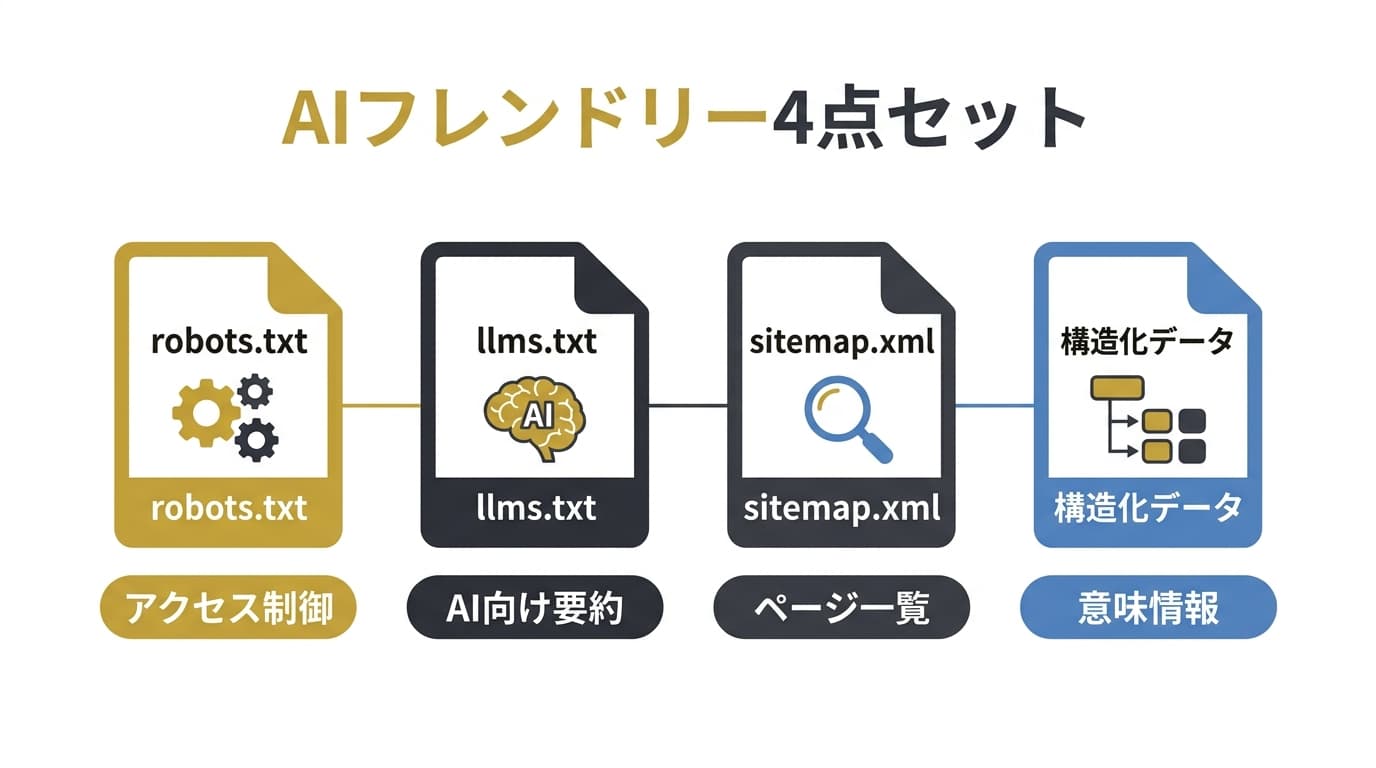
4点セット設計——robots.txt + llms.txt + sitemap.xml + 構造化データ
AIに「読まれる」サイトを設計するには、単一のファイルではなく、4つの要素を連携させた統合設計が必要です。それぞれの役割と連携を整理します。
各要素の役割
| 要素 | 役割 | AIに対する機能 | 設置場所 |
|---|---|---|---|
| robots.txt | アクセス制御 | 「誰がクロールしてよいか」を宣言 | /robots.txt |
| llms.txt | AI向けガイド | 「何を優先的に読んでほしいか」を宣言 | /llms.txt |
| sitemap.xml | ページ一覧 | 「どこに何があるか」を網羅的に提示 | /sitemap.xml |
| 構造化データ | ページ内容の意味付け | 「各ページの内容は何か」を機械可読に提示 | 各HTMLページ内 |
連携設計のポイント
1. robots.txtでAIクローラーを許可し、llms.txtへの導線を確保するrobots.txtでAIクローラーを許可したうえで、llms.txtを設置します。AIクローラーの中には、サイトにアクセスした際にまず /llms.txt の存在を確認するものがあります。robots.txtで /llms.txt をDisallowにしないよう注意してください。
llms.txtに掲載する代表コンテンツは、必ずsitemap.xmlにも含まれている必要があります。sitemap.xmlに存在しないURLをllms.txtに記載すると、AIがアクセスした際に404になるリスクがあります。
3. 構造化データでページ単位の理解を深めるllms.txtがサイト全体のガイドマップなら、構造化データは各ページの「名刺」です。AIがllms.txtで代表コンテンツを発見し、そのページにアクセスしたとき、構造化データ(JSON-LD)がページの種類・著者・更新日・FAQなどを機械的に伝えます。
特にAI引用に効果が高い構造化データは以下の4つです。
- Article: 記事の著者、公開日、更新日、見出し画像を明示
- FAQPage: よくある質問と回答のペアをマークアップ。AIが回答内に引用しやすい形式
- HowTo: 手順型コンテンツの各ステップをマークアップ
- Organization: サイト運営組織の名前、URL、ロゴ、連絡先を明示
| 要素 | 推奨更新頻度 | 更新トリガー |
|---|---|---|
| robots.txt | 四半期に1回 | 新規AIクローラーの出現、ポリシー変更 |
| llms.txt | 月1回または記事公開時 | 代表コンテンツの追加・入替え |
| sitemap.xml | 記事公開のたびに自動更新 | CMS連携で自動化推奨 |
| 構造化データ | 記事公開のたびに自動付与 | テンプレートに組み込んで自動化 |
sitemap.xmlと構造化データはCMSやビルドシステムで自動生成するのが基本です。llms.txtも、CMSのビルド時にカテゴリ情報と人気記事を自動取得して生成する仕組みを構築すると、運用負荷がほぼゼロになります。
AIフレンドリー度チェックリスト——15項目
自社サイトが「AIに読まれやすい状態」になっているかを確認するためのチェックリストです。各項目を確認し、未対応の項目から優先的に実装してください。
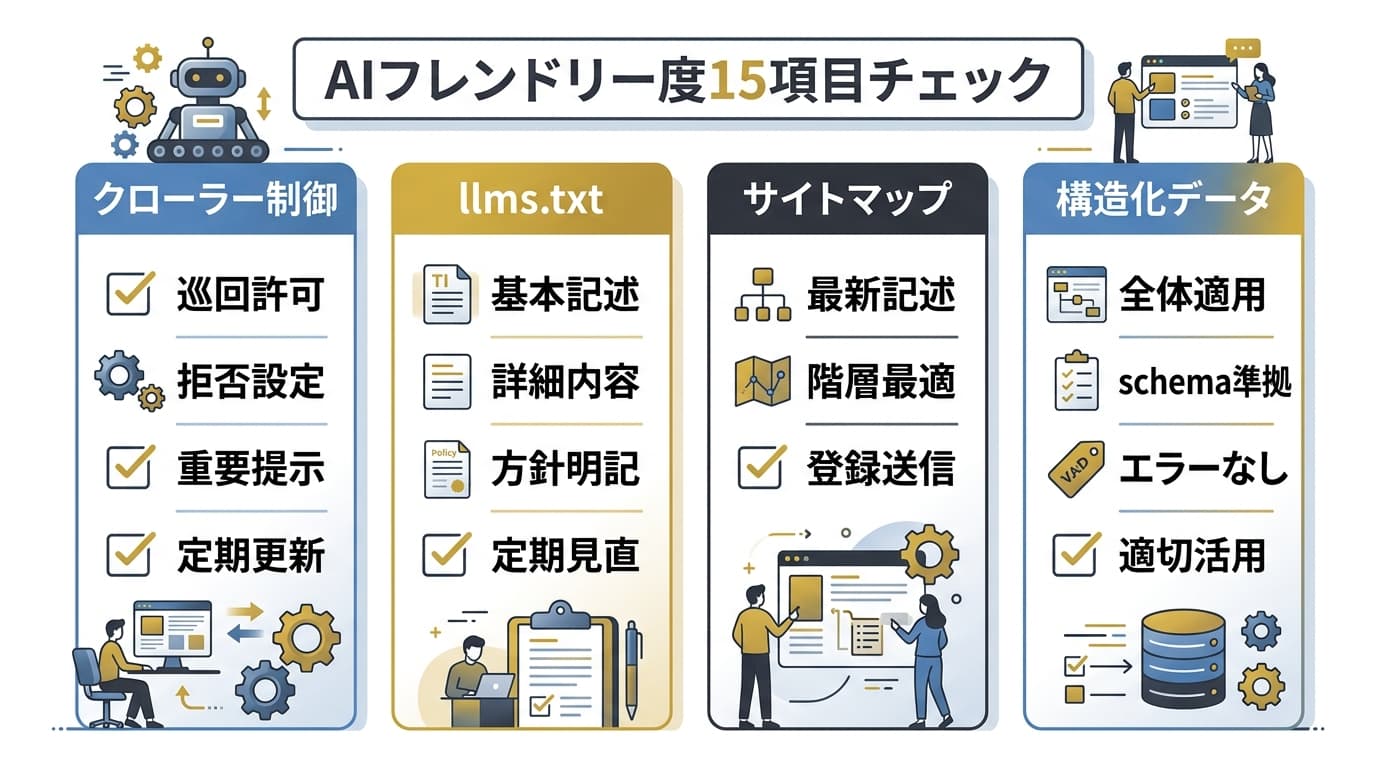
クローラー制御(4項目)
- 1. robots.txtでカテゴリAのAIクローラー(ChatGPT-User, PerplexityBot, ClaudeBot)を許可しているか
- 2. robots.txtでカテゴリCのAIクローラー(Bytespider, CCBot)をブロックしているか
- 3. llms.txtをサイトルートに設置し、サイト概要と代表コンテンツを記載しているか
- 4. robots.txtで
/llms.txtへのアクセスをブロックしていないか
サイト構造・技術基盤(4項目)
- 5. sitemap.xmlが最新の状態で自動更新されているか
- 6. すべてのページがSSR/SSGで静的HTMLとして配信されているか(CSRのみのSPAはAIクローラーが読めない可能性あり)
- 7. ページ表示速度がCore Web Vitalsの基準を満たしているか(遅いページはクロール頻度が下がる)
- 8. HTTPS配信になっているか(HTTP配信はAIクローラーがスキップする場合あり)
構造化データ(3項目)
- 9. 記事ページにArticleスキーマ(著者、公開日、更新日)を実装しているか
- 10. FAQ形式のコンテンツにFAQPageスキーマを実装しているか
- 11. 手順型コンテンツにHowToスキーマを実装しているか
コンテンツ品質(4項目)
- 12. 各セクションの冒頭50字以内に「〜とは、〜である」形式の定義文を置いているか
- 13. 主張に数値・出典・実測データを添えているか(「効果があります」ではなく「CTRが3.2%から7.8%に改善」)
- 14. 著者情報・更新日・連絡先が明示されているか
- 15. 記事の更新日が直近6ヶ月以内か(古い記事はAIが引用を避ける傾向あり)
スコアリング目安
- 13〜15項目対応: AIフレンドリー度A。AI検索での引用を期待できる水準
- 9〜12項目対応: AIフレンドリー度B。基本的な対応は完了しているが改善余地あり
- 5〜8項目対応: AIフレンドリー度C。優先度の高い項目から順次対応が必要
- 4項目以下: AIフレンドリー度D。AI検索からの引用はほぼ期待できない状態
許可/ブロックの判断フロー——5つの質問で決める
「どのAIクローラーを許可し、どれをブロックすべきか」は、サイトのビジネスモデルとコンテンツ戦略によって異なります。以下の5つの質問に答えることで、自社に最適な設定を導き出せます。
各質問の詳細
Q1: AI検索からの流入・引用が欲しいか?Noの場合は明確です。パターン3(全面ブロック)を選択します。これは「ニュースの有料記事のみを販売しており、無断引用は収益損失に直結する」「研究論文の独占配信プラットフォームで、引用ではなくサイト訪問そのものが価値」といったケースです。
Yesの場合はQ2に進みます。多くの事業会社サイト、メディアサイト、SaaS企業のオウンドメディアはYesです。
Q2: 有料コンテンツがあるか?有料コンテンツ(会員限定記事、有料レポート、有料教材など)がある場合は、パターン2を選択します。無料コンテンツはAI検索での引用を通じて集客に使い、有料コンテンツは学習・引用の両方からブロックして価値を保護します。
Q3: AIモデルの学習に使われてよいか?ここが最も悩ましい判断です。許可するメリットは「AIが自社コンテンツを深く理解し、引用の精度が上がる」こと。許可しないメリットは「コンテンツの知的財産を保護できる」ことです。
判断の目安として、引用されることで自社の認知・権威性が上がるコンテンツ(ブログ、ガイド記事、ナレッジベース)は許可が有利です。一方、コンテンツ自体が商品であるもの(有料レポート、オリジナルデータセット)は拒否が妥当です。
Q4: サーバー負荷に余裕があるか?カテゴリBのクローラーを許可すると、クロール頻度が増加します。小規模サーバーで運用している場合は、カテゴリAのみ許可し、カテゴリBはCDN導入後に段階的に解放する戦略が安全です。
実装ロードマップ——週単位の3ステップ
ここまでの内容を、実務で実行する際の優先順位とスケジュールに落とし込みます。
Week 1: 最低限の基盤整備
- robots.txtを確認し、カテゴリAのAIクローラー(ChatGPT-User, PerplexityBot, ClaudeBot)が許可されているか確認・修正する
- カテゴリCのAIクローラー(Bytespider, CCBot)をブロックするルールを追加する
- llms.txtのドラフトを作成し、サイトルートに設置する
所要時間の目安: 2〜4時間
Week 2: 構造化データとsitemap整備
- 主要記事ページにArticleスキーマを実装する(著者、公開日、更新日)
- FAQ形式のコンテンツにFAQPageスキーマを追加する
- sitemap.xmlが自動更新されていることを確認する
- Google Rich Results Testで構造化データの検証を行う
所要時間の目安: 4〜8時間(記事数に依存)
Week 3: コンテンツ最適化とモニタリング開始
- トラフィックの多い上位10記事を対象に、冒頭の定義文を50字以内で追加する
- 主張に数値・出典が不足しているセクションを補強する
- ChatGPT / Perplexity / Gemini で自社の主要キーワードを検索し、引用状況のベースラインを記録する
- 週次のモニタリングルーチンを設定する
所要時間の目安: 6〜10時間
よくある失敗パターンと対処法
失敗1: AIクローラーを全部ブロックしていた
最も多い失敗です。「よくわからないボットはブロック」というセキュリティポリシーで、GPTBot・ClaudeBot・PerplexityBotもまとめてDisallowにしてしまうケースです。対処は単純で、カテゴリAのクローラーを許可に変更し、1〜2週間でAI検索の引用状況を確認します。
失敗2: llms.txtに全記事を列挙した
数百本の記事URLをすべてllms.txtに記載してしまうケースです。LLMのコンテキストウィンドウには限りがあるため、情報が多すぎると逆に重要コンテンツが埋もれます。代表コンテンツ5〜10本に絞り、残りはsitemap.xmlに任せましょう。
失敗3: 構造化データなしでllms.txtだけ設置した
llms.txtはサイトレベルのガイドマップであり、ページレベルの理解は構造化データが担います。llms.txtだけ設置しても、各ページの内容をAIが正確に把握できなければ引用の精度は上がりません。4点セットの連携が重要です。
失敗4: 設置後にモニタリングしていない
llms.txtとrobots.txtを設置して「終わり」にしてしまうケースです。AI検索の挙動は頻繁に変わるため、週次〜月次でのモニタリングが不可欠です。最低限、ChatGPT・Perplexity・AI Overviewでの自社キーワード検索を月1回は実施してください。
まとめ——AIに「読まれる」サイトの技術標準
2026年のサイト設計は、従来のSEOに加えて「AIに読まれる設計」という新しいレイヤーが必須になりました。この記事で解説した内容を3点に要約します。
1. AIクローラーは目的別に3カテゴリに分け、許可/ブロックを判断するリアルタイム検索系(ChatGPT-User, PerplexityBot, ClaudeBot)は許可、学習データ系はビジネス判断、高負荷系(Bytespider, CCBot)はブロック。この3分類を基本方針にします。
2. llms.txtで「AIに読んでほしい情報」を積極的に宣言するrobots.txtの「拒否」だけでなく、llms.txtによる「招待」を組み合わせることで、AIの理解精度と引用率を向上させます。サンプルコードをベースに、自社サイトに最適化したllms.txtを作成してください。
3. robots.txt + llms.txt + sitemap.xml + 構造化データの4点セットで設計する4つの要素は独立ではなく連携して機能します。1つだけ整備しても効果は限定的です。4点セットを一体的に設計し、運用サイクルに組み込むことで、AI検索時代の技術基盤が完成します。
LLMO対策の全体フレームワークとGEO施策の実装手順と合わせて読むことで、AI検索最適化の全体像を把握できます。まずはWeek 1のrobots.txt確認とllms.txt設置から始めてください。

この記事の著者
Agentic Base 編集部
AIエージェントとWebメディア運用の知見を活かし、実践的なナレッジを発信しています。



