「Google検索では1位なのに、Perplexityにもchatgptにも引用されない」——2026年、この悩みを持つマーケターが急増しています。原因は明確です。SEOとGEOは別の競技だからです。検索順位を上げるSEOと、AIに引用されるGEOでは、最適化の設計思想が根本的に異なります。
この記事では、GEO(Generative Engine Optimization)対策の全体像を実装レベルで解説します。GEO・LLMO・AIO・AEOの4概念整理、AI検索エンジン別の引用ロジック比較、C-CITEモデルとの接続、そして25項目のチェックリスト。SEO会社のポジショントーク記事ではなく、事業会社のマーケター・SEO担当が明日から使える設計図として読んでください。
なお、GEOの各論となるLLMO対策の詳細は LLMO対策完全ガイド、Google AI Overview特化のAIO対策は AIO対策完全ガイド で扱っています。概念の全体マップは SEO vs LLMO vs AIO も参照してください。本記事はこれら3記事の統合実装ガイドとして位置付けています。
GEOとは何か——SEOとの本質的な違い
GEO(Generative Engine Optimization)とは、Perplexity・ChatGPT・Gemini・Google AI Overviewなどの生成AI検索エンジンに、自社コンテンツを引用させるための最適化です。 日本語圏ではLLMO(Large Language Model Optimization)とも呼ばれ、両者は実質同義です。
SEOとGEOの最大の違いを一言で言えば、「順位を上げる」と「引用される」の違いです。
| 比較軸 | SEO | GEO |
|---|---|---|
| ゴール | 検索結果の順位向上 | AI回答内での引用・言及 |
| 対象 | Google、Bing | Perplexity、ChatGPT、Gemini、AI Overview |
| 評価基準 | リンク・キーワード・CTR | 情報構造・一次データ・明瞭性 |
| ランキング | 1位〜10位の順位戦 | 引用されるか/されないかの二値 |
| クリック | クリック→流入が前提 | ゼロクリックでも引用価値あり |
| 施策寿命 | 数ヶ月〜数年 | AIのモデル更新で変動しうる |
この違いが「順位1位なのに引用されない」という倒錯を生んでいます。SEOでは被リンク・ドメイン権威・キーワード密度が決定的に効きますが、GEOではこれらの要素だけでは不十分です。AIは情報の構造、結論の明瞭性、一次データの有無、出典の信頼性を基準に引用ソースを選びます。
つまり、GEO対策の本質は「SEOの延長」ではなく「引用される設計」です。
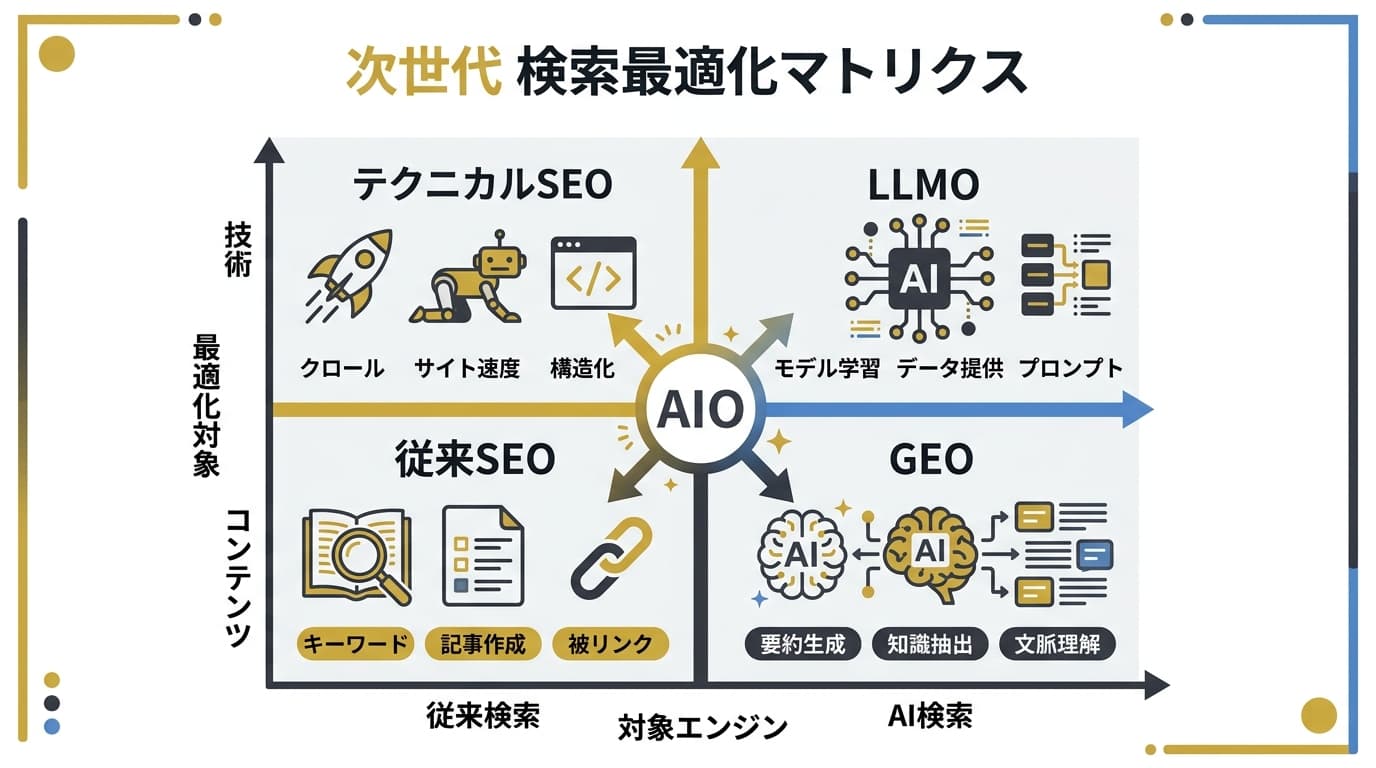
GEO・LLMO・AIO・AEO——4概念の違いを整理する
市場では用語が混在しており、「GEOとLLMOは違うのか」「AIOとは何か」という混乱が続いています。まず4つの概念を1枚の表で整理します。
| 用語 | 正式名称 | 登場時期 | スコープ | 対象エンジン | 本記事での扱い |
|---|---|---|---|---|---|
| GEO | Generative Engine Optimization | 2023〜 | 生成AI検索全般 | Perplexity、ChatGPT、Gemini、AI Overview | 本記事の主題(LLMOと同義) |
| LLMO | Large Language Model Optimization | 2023〜 | 生成AI検索全般 | GEOと同一 | GEOと同義(日本語圏の呼称) |
| AIO | AI Overview Optimization | 2024〜 | Google AI Overview 特化 | Google AI Overview のみ | GEO/LLMOのサブセット |
| AEO | Answer Engine Optimization | 2018〜 | 回答エンジン全般 | 強調スニペット、音声アシスタント等 | 歴史的前身(GEOに吸収) |
実務上の整理:
- GEO = LLMO。呼称の違いだけで中身は同じ。北米ではGEO、日本語圏ではLLMOが主流
- AIO は GEO/LLMO のサブセット。Google AI Overviewに特化した狭義の最適化(詳細は AIO対策ガイド)
- AEO は GEO の前身。強調スニペットや音声アシスタント時代の概念で、2026年時点ではGEOに吸収済み
- SEO と GEO は別物だが補完関係。SEO資産(順位・被リンク)はGEOにも間接的に効く
この整理を持っていれば、SEO会社ごとに用語の定義がバラバラでも混乱しません。SEO vs LLMO vs AIO の概念ハブ記事 ではさらに詳細な施策レベルの重複・差分を解説しています。
なぜ今GEO対策が必要なのか——3つの構造変化
1. 検索トラフィック25%減の予測
Gartner は2026年までに検索エンジン経由のトラフィックが25%減少すると予測しています。主因は生成AI検索の普及です。ユーザーがGoogleで検索する代わりに、Perplexity や ChatGPT に直接質問する行動が定着しつつあります。
実際、2025年末から2026年初にかけてPerplexityの月次アクティブユーザーは急増し、ChatGPT SearchやGemini Deep Researchも検索行動の受け皿として拡大しています。「Googleで調べる」から「AIに聞く」へのシフトは予測ではなく、すでに起きている現象です。
2. ゼロクリック率6割超の現実
Google AI Overview がSERP上部に表示されるクエリでは、ユーザーの6割以上がリンクをクリックせずにAI要約だけで情報収集を完了するという観測データが報告されています。いわゆるゼロクリック化です。
これが意味するのは、SEOで1位を取ってもトラフィックが来ないケースが増えているということです。検索順位は依然として重要ですが、それだけでは不十分になりました。AI Overview内で出典として引用される、あるいはPerplexityの回答でインライン引用されることが、新しい「露出」の形になっています。
3. 引用は順位と無関係に起きる
AIは「検索順位が高い順」に引用するわけではありません。Perplexityは一次データと数値を含む文を、ChatGPTは構造化された定義文を、Geminiは網羅的で最新の記事を優先して引用します。
順位は3位でも、引用構造が整っていれば1位のサイトより先に引用されることが実際に起きています。これはSEOにはなかった構造です。逆に言えば、順位が低くてもGEO対策次第で引用される——SEO弱者にとってのチャンスでもあります。
AI検索エンジン別の引用ロジック比較
GEO対策の解説記事がほぼ触れていない最重要論点です。Perplexity・ChatGPT・Gemini・Google AI Overview・Copilotは、それぞれ引用ロジックが異なります。 2026年4月時点の観測ベースで整理します。

| AI検索エンジン | 引用の積極度 | 引用形式 | 最も重視する要素 | 対策の要点 |
|---|---|---|---|---|
| Perplexity | 非常に高い | 文中インライン引用+出典リスト | 一次データ・数値・新鮮さ | 実測値入りの短文、更新日明示、図表 |
| ChatGPT Search | 中〜高 | 回答末尾の出典リスト | 構造化データ・信頼性 | FAQ schema、著者情報、結論ファースト |
| Gemini(Deep Research) | 中〜高 | 要約+出典リンク | 網羅性・新鮮さ・権威性 | 包括的な長尺記事、更新日、E-E-A-T |
| Google AI Overview | 高 | SERP上部の要約+引用元 | Schema・SERP順位・E-E-A-T | JSON-LD、既存SEO資産、要約段落 |
| Microsoft Copilot | 中 | 回答中の脚注+出典 | Bing順位・構造化・信頼性 | Bing SEO、著者情報、FAQ schema |
エンジン別の攻略ポイント
Perplexityは最も引用に積極的なエンジンです。インライン引用(文中に出典番号を埋め込む形式)を多用するため、「引用されやすい短い数値入りの文」を記事内に散りばめると効果的です。「CVRが3.2%から7.8%に改善した」「月間100万PVのサイトで検証」のような一次データ付きの文が優先的に引用されます。
ChatGPT Searchは構造化データを重視します。FAQPage schema、HowTo schema、Article schema の実装が引用率に直結します。また、著者情報と更新日が明示されている記事を優先する傾向があり、匿名・日付なしの記事は引用されにくいです。
Gemini Deep Researchは網羅性と新鮮さを重視します。特定トピックを深掘りした長尺記事で、かつ更新日が新しいものが引用されやすい傾向があります。Google の検索インデックスと連動しているため、SEO資産がそのまま効く面もあります。
Google AI Overviewは既存SEOとの相関が最も強いエンジンです。SERP上位に表示されている記事が引用されやすく、JSON-LDの実装状況、E-E-A-T シグナル(著者・組織・更新日)も強く影響します。詳細は AIO対策ガイド で解説しています。
Microsoft CopilotはBingの検索インデックスをベースにしています。Bing Webmaster Toolsでのインデックス状況を確認し、Bing向けのSEO施策を併せて行うと効果的です。
実務上の示唆:狙うエンジンを1つ決める
すべてのAI検索エンジンに同時に最適化するのは非効率です。自社のターゲットユーザーが最も使うAI検索エンジンを1つ選び、そこから着手するのが正解です。
- BtoB・リサーチャー向け → Perplexity を最優先
- 一般消費者向け → Google AI Overview を最優先
- 技術者・開発者向け → ChatGPT Search を最優先
- エンタープライズ向け → Microsoft Copilot を最優先
1つを攻略したら横展開します。引用ロジックの共通部分(結論ファースト・構造化データ・一次データ)を先に整備すれば、2つ目以降の展開は差分対応だけで済みます。
C-CITEモデルとの接続——GEO対策の設計フレームワーク
GEO対策の施策を体系的に整理するフレームワークとして、LLMO対策ガイド で提唱したC-CITEモデルを使います。GEO対策のすべての施策は、この5要素のいずれかに分類できます。
| C-CITE要素 | GEO対策での具体施策 | 対応するAI検索エンジン |
|---|---|---|
| C: Crawler Access | robots.txt でAIクローラー許可、llms.txt 配置 | 全エンジン共通 |
| C: Concise Answer | 冒頭50字定義文、結論ファースト、要約段落 | 全エンジン共通(特にPerplexity) |
| I: Inline Evidence | 一次データ、実測値、出典リンク、図表 | Perplexity、Gemini |
| T: Trust Signals | 著者情報、更新日、E-E-A-T、組織情報 | ChatGPT、AI Overview |
| E: Evaluation Loop | 週次AI引用モニタリング、改修サイクル | 全エンジン共通 |
C-CITEモデルの強みは、施策の優先順位を明確にできることです。C1(クローラー許可)→ C2(冒頭定義)→ I(一次データ)→ T(信頼シグナル)→ E(モニタリング)の順で整備すれば、技術的な負債を作らずに進められます。
GEO実装の具体的手順
ここからが実装パートです。C-CITEモデルの5要素に沿って、具体的な手順を解説します。
ステップ1: AIクローラーの許可(Crawler Access)
AIに読まれなければ引用されません。最初にやるべきは、robots.txt での AI クローラー許可です。
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: PerplexityBot
Allow: /
User-agent: Google-Extended
Allow: /
User-agent: Bytespider
Allow: /
驚くほど多くのサイトが、AI クローラーをブロックしたままになっています。特に大手メディアや企業サイトでは、セキュリティポリシーの一環として一律ブロックしているケースが散見されます。まず自社の robots.txt を確認してください。ここが塞がっていたら、他のすべての施策が無意味です。
ステップ2: llms.txt の配置
サイトルートに /llms.txt を配置し、AIが優先的に参照すべきURLとサイト説明を記述します。
# 自社サイト名
> サイトの説明文(1〜2行)
## Docs
- [記事タイトル1](https://example.com/article1): 記事の概要説明
- [記事タイトル2](https://example.com/article2): 記事の概要説明
- [サービスページ](https://example.com/service): サービスの概要
llms.txt は2026年時点ではまだプロポーザル段階ですが、Anthropic(ClaudeBot)やPerplexityBot が参照を開始しており、早期実装のメリットが大きい施策です。主要記事20〜30本のURLを記載し、四半期ごとに更新するのが運用の目安です。
ステップ3: 構造化データの実装
FAQPage、HowTo、Article の3つのJSON-LDを主要ページに実装します。
FAQPage schema(最も引用率に直結):
{
"@context": "https://schema.org",
"@type": "FAQPage",
"mainEntity": [{
"@type": "Question",
"name": "GEO対策とは何ですか?",
"acceptedAnswer": {
"@type": "Answer",
"text": "GEOとは、Perplexity・ChatGPT・GeminiなどのAI検索に自社コンテンツを引用させるための最適化です。"
}
}]
}Article schema(著者・更新日の明示):
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "記事タイトル",
"author": {
"@type": "Person",
"name": "著者名"
},
"datePublished": "2026-04-06",
"dateModified": "2026-04-06",
"publisher": {
"@type": "Organization",
"name": "組織名"
},
"inLanguage": "ja"
}ChatGPT Search は構造化データを特に重視する傾向があるため、FAQ schema の実装は GEO 対策で最もROIが高い技術施策と言えます。
ステップ4: 結論ファーストのコンテンツ設計(Concise Answer)
AIが引用しやすい文章構造には明確なパターンがあります。
原則1: 冒頭50字定義文各セクション(H2)の冒頭1〜2文で、「〜とは、〜である」の完結した定義文を置きます。AIはこの形式の文を最も引用しやすく、Perplexityのインライン引用で特に効果的です。
原則2: 要約→詳細の二段構造セクションの構造を「要約1段落 → 詳細解説 → 箇条書きまとめ」の形にします。AIが部分引用する際に、要約段落だけで意味が通じる設計です。
原則3: 表と箇条書きの戦略的配置比較情報・仕様情報・手順情報は、必ず表か箇条書きで構造化します。AIは非構造テキストよりも表・リスト形式の情報を引用しやすい傾向があります。
ステップ5: 一次データの埋め込み(Inline Evidence)
AIは抽象的な主張より、具体的な数値・実測値・出典付きのファクトを優先して引用します。
引用されない文:
GEO対策をすると効果があります。多くの企業が取り組んでいます。
引用される文:
当社の検証では、C-CITEモデルに基づくGEO対策実施後3ヶ月で、Perplexity経由の流入が月間120セッションから480セッションに増加(4倍)しました。
違いは明確です。後者には数値・期間・出典元(自社データ)・比較が含まれています。Perplexityは特にこの種の一次データ付き文を好んで引用します。
自社に一次データがない場合は、公的機関の統計データや調査レポートへの出典リンクを明示することで代替できます。「出典なしの主張」は引用されにくいと覚えてください。
ステップ6: 信頼シグナルの整備(Trust Signals)
著者情報、更新日、組織情報、出典リンク——この4つがAIの信頼判断に直結します。
- 著者プロフィール: 記事ごとに著者名・肩書き・専門領域を明示。Person schema の実装が理想
- 更新日(updatedAt): 記事のフロントマターと本文の両方で更新日を明示。Gemini は更新日を特に重視
- 組織情報: サイト全体に Organization schema を実装し、運営元の信頼性を明示
- 出典リンク: 外部の信頼できる情報源(公的機関、学術論文、業界レポート等)へのリンク
匿名記事・日付なし記事・出典なし記事は、2026年のAI検索では引用候補から外れやすくなっています。
ステップ7: AI回答モニタリングの開始(Evaluation Loop)
GEO対策は「やって終わり」ではありません。週次でAI回答をモニタリングし、引用状況を記録し、改修に反映する運用ループが必要です。
モニタリングの手順:
- 自社のターゲットキーワード(10〜20語)を選定
- 週1回、以下の4つのAI検索で各キーワードを検索
- Perplexity
- ChatGPT(Search機能)
- Google(AI Overview表示の確認)
- Gemini
- 回答内に自社ドメインが引用されているかを記録
- 引用されていないキーワード×記事の組み合わせを「改修候補リスト」に追加
- 月次で改修を実施し、翌月の引用変化を観測
2026年4月時点では、この手動モニタリングが最も信頼できる方法です。自動化ツール(Ahrefs ブランドレーダー、BrightEdge GEO機能、Perplexity Pro API等)も登場していますが、手動チェックを完全代替するには至っていません。
GEO対策チェックリスト(25項目)
事業会社が自社で実装するための網羅的チェックリストです。技術8項目・コンテンツ9項目・運用8項目の3カテゴリに分けています。必須(★)・推奨(◎)・任意(○)でラベル付けしています。

技術編(8項目)
| # | チェック項目 | 優先度 | C-CITE要素 |
|---|---|---|---|
| 1 | robots.txt で GPTBot を許可 | ★ | C1 |
| 2 | robots.txt で ClaudeBot を許可 | ★ | C1 |
| 3 | robots.txt で PerplexityBot を許可 | ★ | C1 |
| 4 | robots.txt で Google-Extended を許可 | ★ | C1 |
| 5 | /llms.txt をサイトルートに配置 | ◎ | C1 |
| 6 | 全主要ページに FAQPage schema を実装 | ★ | C2 |
| 7 | 記事ページに Article schema(著者・日付含む)を実装 | ★ | T |
| 8 | HowTo ページに HowTo schema を実装 | ◎ | C2 |
コンテンツ編(9項目)
| # | チェック項目 | 優先度 | C-CITE要素 |
|---|---|---|---|
| 9 | 各H2セクション冒頭に50字の定義文を配置 | ★ | C2 |
| 10 | 結論ファーストの段落構成に統一 | ★ | C2 |
| 11 | 記事末にFAQセクションを配置 | ★ | C2 |
| 12 | 一次データ・実測値を文中に明示 | ★ | I |
| 13 | 外部出典への信頼できるリンクを配置 | ◎ | I |
| 14 | 比較情報は表形式で構造化 | ◎ | C2 |
| 15 | 手順情報は番号付きリストで構造化 | ◎ | C2 |
| 16 | 長いセクション後に要約段落(50〜100字)を配置 | ◎ | C2 |
| 17 | 専門用語は初出時に定義を明示 | ○ | C2 |
運用編(8項目)
| # | チェック項目 | 優先度 | C-CITE要素 |
|---|---|---|---|
| 18 | updatedAt / 更新日を全記事に明示 | ★ | T |
| 19 | 著者プロフィール(名前・肩書き・専門領域)を整備 | ★ | T |
| 20 | 組織情報(Organization schema)を実装 | ◎ | T |
| 21 | 週次でPerplexityの引用状況をチェック | ★ | E |
| 22 | 週次でChatGPT Searchの引用状況をチェック | ◎ | E |
| 23 | 週次でGoogle AI Overviewの引用状況をチェック | ★ | E |
| 24 | 引用されていない記事の改修候補リストを月次更新 | ◎ | E |
| 25 | 3ヶ月に1度の記事見直しサイクルを運用 | ◎ | E |
★が必須の12項目です。まずここから着手してください。 多くのサイトは★項目の半分もカバーできていません。12項目をすべて実装するだけで、競合の大半を上回る引用率を得られます。
GEO対策のよくある失敗パターン
多くの企業がGEO対策で陥る失敗パターンを5つ整理します。事前に知っておくだけで回避できます。
失敗1: 「SEOの延長」として取り組む
最も多い失敗です。「SEOで上位だからAIにも引用されるだろう」と考え、GEO固有の施策(クローラー許可・llms.txt・結論ファースト構成)を怠るパターン。SEO1位でもAIに引用されない事例は多数あります。GEOはSEOとは別の設計として捉えてください。
失敗2: 全エンジンに同時最適化しようとする
Perplexity・ChatGPT・Gemini・AI Overview・Copilotのすべてに同時対応しようとして、どれも中途半端になるパターン。まず1つのエンジンに集中し、引用を獲得してから横展開するのが正解です。
失敗3: 技術施策だけで終わる
robots.txt や構造化データを実装して満足し、コンテンツの書き方を変えないパターン。AIクローラーにアクセスを許可しても、コンテンツが引用しにくい構造(結論後置・曖昧な主語・長段落)のままでは引用されません。 技術とコンテンツは車の両輪です。
失敗4: モニタリングをしない
GEO対策を一度実施して「あとは待つだけ」になるパターン。AIの引用ロジックはモデル更新で変動するため、週次の引用チェック→月次の改修というサイクルを回さないと効果が持続しません。C-CITEモデルの「E(Evaluation Loop)」を軽視すると、せっかくの施策が陳腐化します。
失敗5: 一次データなしのまとめ記事を量産する
「GEO対策まとめ」「AI検索対策10選」のような、他記事の要約だけで構成された記事を量産するパターン。AIは一次情報(自社の実測データ・独自の分析・オリジナルの図表)を持つ記事を優先的に引用します。二次情報の寄せ集めでは、AIの引用候補リストに入りにくいです。
GEO対策の効果測定とKPI設計
GEO対策の効果は、従来のSEO指標(順位・PV・CTR)だけでは測定できません。新しいKPIフレームワークが必要です。
第1層: 直接指標(AI引用)
- AI回答内での自社ドメイン引用回数(週次手動チェック)
- 引用が発生したキーワード数とその推移
- 引用元エンジン別の分布(Perplexity / ChatGPT / Gemini / AI Overview)
第2層: 間接指標(トラフィック)
- Perplexity 経由の流入セッション数(GA4 リファラー
perplexity.ai) - ChatGPT 経由の流入セッション数(GA4 リファラー
chatgpt.com) - 指名検索の増加率(ブランド名+サービス名の検索ボリューム推移)
第3層: ビジネス指標
- AI経由トラフィックからのCV数・CV率
- AI引用による被リンク獲得数
- ブランド認知度の変化(指名検索ボリュームで代替計測)
現実的なモニタリング体制: 2026年4月時点では、第1層は手動チェック、第2層はGA4、第3層はGoogle Search Console+営業データの組み合わせが実務解です。すべてを自動化する標準ツールはまだ成熟していません。
3ヶ月ロードマップ——今週から始めるGEO対策
最後に、小中規模サイト(50〜200記事)を想定した3ヶ月の実装ロードマップを提示します。
月1: 技術基盤の整備(工数目安: 3〜5人日)
robots.txtで主要AIクローラー(GPTBot・ClaudeBot・PerplexityBot・Google-Extended)を許可/llms.txtをサイトルートに配置(主要記事20本を記載)- 主要記事20本に FAQPage schema と Article schema を実装
- 著者プロフィールページを整備、Person schema を実装
月2: コンテンツ改修(工数目安: 10〜15人日)
- 主要記事20本の冒頭に50字定義文を配置
- 各記事末にFAQセクション(3〜5問)を追加
- 一次データ・実測値がない記事に自社データを追加
- 比較情報・手順情報を表・箇条書きに構造化
- 結論ファースト構成に統一リライト
月3: モニタリング開始と横展開(工数目安: 3〜5人日+継続運用)
- 週次のAI引用モニタリングを開始(ターゲットKW 10〜20語)
- 引用されていない記事の改修候補リストを作成
- 改修→再モニタリングのPDCAサイクルを確立
- 残りの記事への段階的な横展開計画を策定
- ゼロクリックKPIダッシュボードを構築(引用回数・指名検索・AI経由流入の3指標)
合計工数目安: 16〜25人日(内製であれば、Web担当者1名が月15〜20時間を充てれば3ヶ月で完了します)。
まとめ——GEO対策は「引用される設計」
GEO対策の本質は、検索順位を上げることではなく、AIに引用される情報設計です。C-CITEモデル(Crawler Access → Concise Answer → Inline Evidence → Trust Signals → Evaluation Loop)の5要素を順番に整備すれば、3ヶ月後にはPerplexity・ChatGPT・Google AI Overviewでの引用頻度が明確に変わります。
今日からできる3つのアクション:
- 今すぐ(5分): 自社の
robots.txtを開き、GPTBot・ClaudeBot・PerplexityBot が許可されているか確認する - 今週(2時間): PV上位3記事に FAQセクションと冒頭50字定義文を追加する
- 今月(1日): ターゲットKW 10語を選び、Perplexity・ChatGPT・AI Overviewでの引用有無を初回チェックする
GEOはSEOの敵ではなく、SEO資産をAI引用に転換する追加レイヤーです。 既存記事を捨てる必要はありません。C-CITEモデルに従って順次アップデートしていけば、AI検索時代の露出チャネルを確保できます。
関連記事として LLMO対策完全ガイド、AIO対策完全ガイド、SEO vs LLMO vs AIO の概念ハブ も併せてお読みください。
Agentic Baseでは、GEO対策の設計支援からC-CITEモデルに基づいた記事改修、25項目チェックリストの自社カスタマイズまで対応しています。 お問い合わせはこちら →
よくある質問(FAQ)
GEO対策とは何ですか?SEOとどう違いますか?
GEO(Generative Engine Optimization)対策とは、Perplexity・ChatGPT・Gemini・Google AI OverviewなどのAI検索エンジンに自社コンテンツを引用させるための最適化です。SEOがGoogleの検索順位向上を目的とするのに対し、GEOはAI回答内での引用・言及をゴールとします。順位ではなく「引用されるかどうか」が評価軸であり、結論ファーストの構成、構造化データ、一次データの明示など、SEOとは異なる設計思想が必要です。
GEOとLLMOとAIOは何が違いますか?
GEOとLLMOは実質同義で、生成AI検索全般への引用最適化を指します。GEOは北米発の呼称、LLMOは日本語圏で広がった呼称です。AIOはGoogle AI Overviewに特化した狭義の最適化で、GEO/LLMOのサブセットに位置します。AEOは強調スニペット・音声アシスタント時代の前身概念で、2026年時点ではGEOに吸収されています。
GEO対策で最初にやるべきことは何ですか?
3つです。(1) robots.txtでGPTBot・ClaudeBot・PerplexityBot・Google-Extendedを許可する(5分)、(2) 主要ページの冒頭に50字の定義文を配置する(数時間)、(3) FAQPage schemaを実装する(1〜2時間)。この3つだけで多くの競合サイトより引用率が上がります。C-CITEモデルのC1(Crawler Access)とC2(Concise Answer)の基礎がこれで揃います。
Perplexityに引用されるにはどうすればよいですか?
Perplexityは一次データ・数値・実測値を含む文を優先的にインライン引用します。「CVRが3.2%から7.8%に改善した」のような具体的な数値入りの短文を記事内に散りばめるのが最も効果的です。加えて、更新日の明示、図表による構造化、出典リンクの整備が引用率を高めます。
GEO対策の効果はどのくらいで出ますか?
技術施策(構造化データ、llms.txt、クローラー許可)は1〜2週間でAIクローラーに反映されます。コンテンツ改修(冒頭定義・FAQ化・一次データ追加)の効果は3〜8週間で観測され始め、Perplexity・ChatGPTでの引用増加として表れます。完全な効果測定には2〜3ヶ月の観測期間が必要です。
GEO対策の費用相場はどれくらいですか?内製は可能ですか?
外注相場は月額10万〜100万円と幅広いですが、工数ベースで分解すると初期の技術実装3〜5人日、コンテンツ改修10〜15人日、月次モニタリング1〜2人日が標準です。内製の場合、既存のWeb担当者1名が月15〜20時間を充てれば、50記事程度のサイトは3ヶ月で一通りカバーできます。外注すべきラインは「構造化データの技術実装に自信がない場合」と「モニタリングの定型化が難しい場合」です。

この記事の著者
Agentic Base 編集部
AIエージェントとWebメディア運用の知見を活かし、実践的なナレッジを発信しています。



