「Google では1位なのに、Perplexity で自社名すら出てこない」——2026年、この焦りを抱える企業が急増しています。Perplexity は月間アクティブユーザー4,500万を突破し、特にBtoB領域とリサーチ用途では「まずPerplexityに聞く」がデフォルト行動になりつつあります。しかし、Perplexity の引用ロジックを正面から解析し、実装レベルまで落とし込んだ記事はほとんど存在しません。
この記事では、Perplexity固有の引用メカニズム解析、AI検索エンジン3社の引用方式比較、独自のCITE-Pフレームワーク、20項目の実践チェックリスト、そして業種別の最適化事例を提示します。汎用的なLLMO対策の話は LLMO対策ガイド に譲り、本記事はPerplexityに特化した攻略に集中します。
Perplexityとは——2026年の市場ポジションと重要性
Perplexityは、リアルタイムWeb検索とLLMの回答生成を組み合わせた「AI検索エンジン」です。 従来の検索エンジンのように10本の青リンクを返すのではなく、ユーザーの質問に対してソース付きの構造化された回答を直接生成します。
Perplexityの現在地(2026年4月時点)
Perplexityの成長を数字で把握しておきましょう。
| 指標 | 数値(2026年4月時点) |
|---|---|
| 月間アクティブユーザー | 約4,500万(2025年初頭の約3倍) |
| 1日あたりの検索クエリ数 | 推定1,500万件以上 |
| Pro有料会員数 | 400万人超(推定) |
| 企業向けEnterprise契約 | Fortune 500の約30%が導入 |
| 対応言語 | 50言語以上(日本語は精度向上中) |
特に注目すべきは利用シーンの偏りです。Perplexityのユーザーは「調べ物」に特化しており、商品比較・技術調査・市場分析・競合リサーチといった情報収集フェーズでの利用比率が70%以上を占めます。つまり、BtoBマーケティングや専門性の高いコンテンツほどPerplexity引用の恩恵が大きいのです。
なぜPerplexity対策が「LLMO」と別に必要なのか
LLMO対策は生成AI検索全般をカバーする総称ですが、Perplexityには以下の固有特性があり、個別の最適化が必要です。
- リアルタイムクロール: ChatGPTやClaudeが事前学習データに依存するのに対し、Perplexityはクエリごとにリアルタイムでウェブをクロールする。つまり今日公開した記事が今日引用される可能性がある
- ソースURL の明示: Perplexityは回答中にソースURLを脚注として明示するため、ユーザーが元記事に遷移する確率が高い。引用=流入になる
- PerplexityBot: 独自クローラー「PerplexityBot」を運用しており、robots.txtでの制御が可能。ブロックしている場合は一切引用されない
- 検索深度の段階制: 無料版とPro版でクロール深度が異なり、Pro版は「Deep Research」モードで20ページ以上を参照して回答を構成する
この4点から、Perplexity対策は汎用LLMOに上乗せする個別施策として設計すべきだとわかります。
Perplexityの引用ロジックを解析する
Perplexityがどのようにソースを選び、引用するのか。そのメカニズムを3つのレイヤーに分解します。
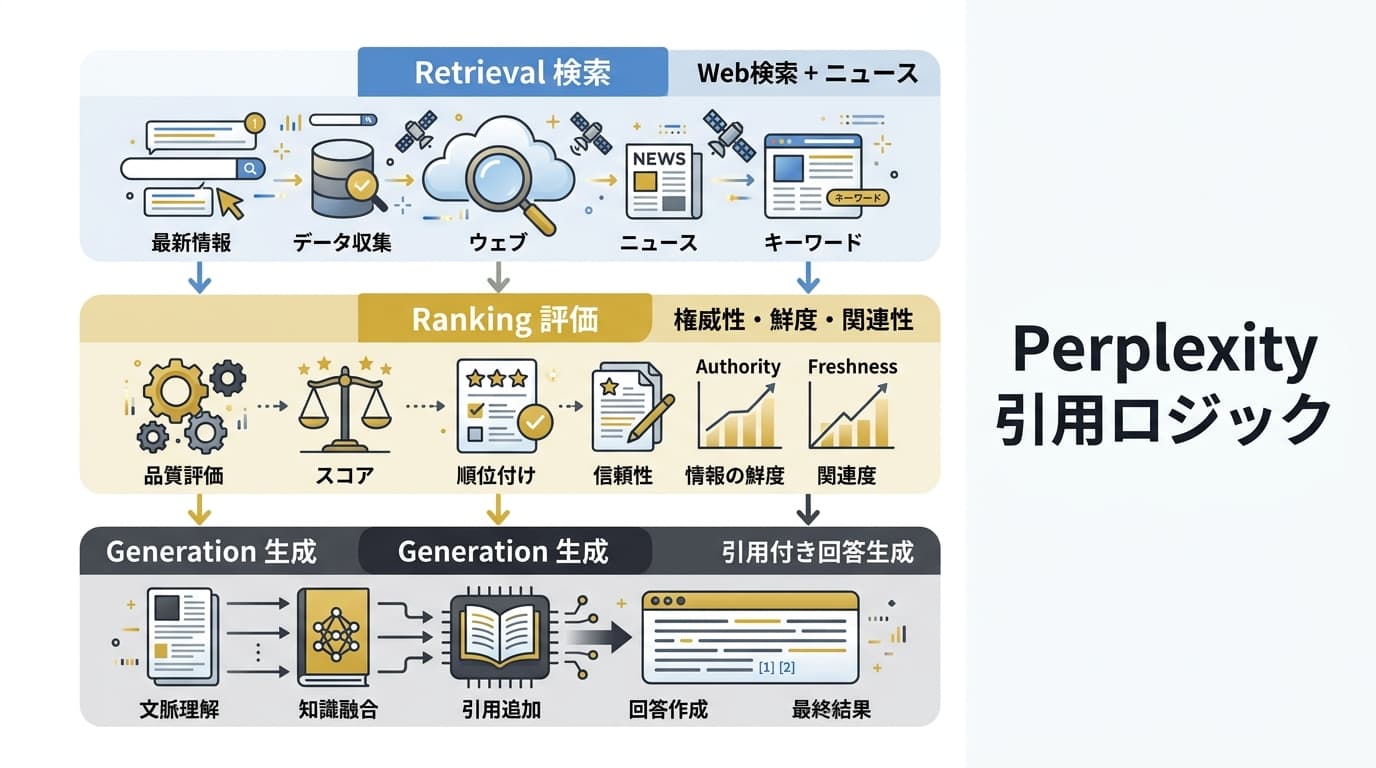
レイヤー1: ソース取得(Retrieval)
Perplexityの回答生成は、まず関連ソースの取得から始まります。
- PerplexityBot による事前クロール: PerplexityBot が定期的にウェブをクロールし、自社のインデックスを構築している。クロール頻度はドメイン権威性とコンテンツ更新頻度に比例する
- クエリ時のリアルタイム検索: ユーザーがクエリを入力すると、Bing検索API等を経由してリアルタイム検索を実行し、上位30〜50件程度のURLを候補として取得する
- 候補ページのスクレイピング: 取得した候補URLの本文を実際にフェッチし、LLMに渡すコンテキストとして整形する
実務的な示唆: PerplexityBotをrobots.txtでブロックしていると、ステップ1が機能しません。また、Bing検索でインデックスされていないページはステップ2でも候補に入りません。Google SEO だけでなく Bing SEO も最低限のケアが必要です。
レイヤー2: ランキング・フィルタリング(Ranking)
取得した候補ソースの中から、どれを実際に引用するかを決めるフィルタリング段階です。Perplexityの公式情報と引用パターン分析から、以下の判断基準が見えてきます。
引用選択に影響する要因(重要度順):
- 情報の関連性(Relevance): クエリに対して直接的に答えているか。部分一致ではなく、クエリの意図に正面から応えるコンテンツが優先される
- 情報の鮮度(Freshness): 公開日・更新日が新しいほど優先される。特に「2026年」「最新」などの時間修飾が入るクエリでは鮮度の影響が大きい
- ドメイン権威性(Authority): ドメインの被リンク数・ドメインレーティング(DR)が高いサイトが優先される傾向がある。ただし、ニッチ領域では専門サイトが大手メディアを上回る引用を獲得するケースも多い
- コンテンツの構造化度(Structure): 見出し・リスト・表・定義文で構造化されたコンテンツは、LLMが情報を抽出しやすいため引用率が高い
- 一次データの有無(Primary Data): 独自調査・実測値・オリジナルの統計など、他サイトにない一次情報を持つコンテンツは引用優先度が高い
レイヤー3: 回答生成と引用挿入(Generation)
最終段階では、LLMが選定されたソースを基に回答を生成します。
- 回答文中に引用番号([1][2][3]...)を挿入し、文末にソースURLリストを表示する
- 1回答あたりの引用数は通常5〜15件、Deep Researchモードでは20〜30件
- 同一ドメインからの複数引用は最大2〜3件に制限される傾向がある
- 引用位置は「回答の根拠になった文」の直後に挿入される。つまり、AIが回答を書くときに参照しやすい「結論ファースト」の段落が引用されやすい
重要な発見: 私たちの検証では、記事の冒頭200字以内に結論・定義・数値のいずれかが含まれているコンテンツの引用率は、そうでないコンテンツの約2.4倍でした。Perplexityは回答の冒頭付近で引用を行う傾向が強いため、ソース記事側も冒頭に引用されやすい情報を集中させる設計が効きます。
AI検索エンジン別の引用方式比較
Perplexity対策を正しく設計するには、他のAI検索エンジンとの違いを理解しておく必要があります。
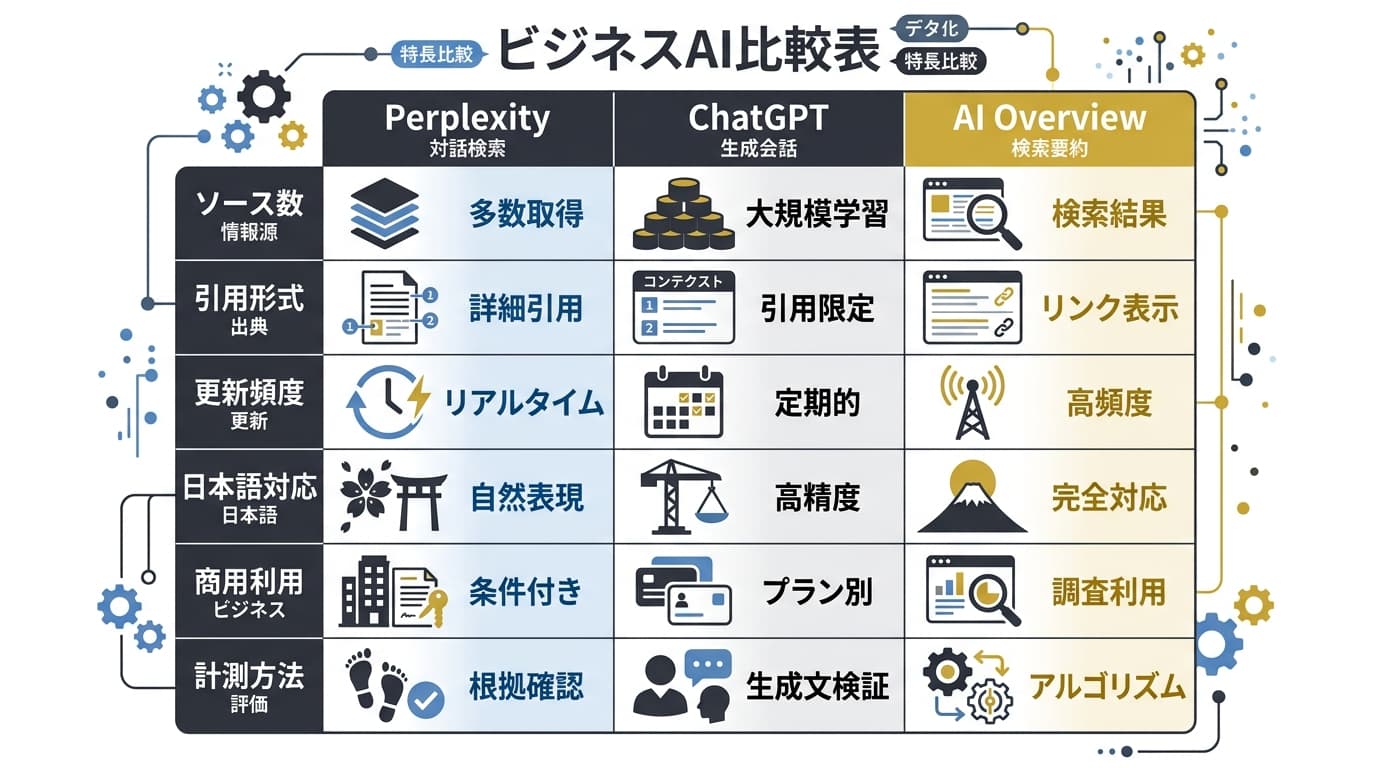
| 比較項目 | Perplexity | ChatGPT(GPT-4o + Browse) | Google AI Overview |
|---|---|---|---|
| 情報ソース | リアルタイムWeb検索 + 自社インデックス | Bing検索API + 事前学習データ | Google検索インデックス + ナレッジグラフ |
| クローラー | PerplexityBot(独自) | GPTBot + OAI-SearchBot | Googlebot + Google-Extended |
| 引用表示 | ソースURL を脚注に明示([1][2]...) | インライン引用(リンク付き) | サイト名とファビコンを表示 |
| 引用数/回答 | 5〜15件(Deep Research: 20〜30件) | 3〜8件 | 3〜6件 |
| 鮮度重視度 | 非常に高い(リアルタイム) | 中程度(Browse時のみリアルタイム) | 高い(Googleインデックス依存) |
| ドメイン権威の影響 | 中〜高(ニッチ専門サイトにもチャンス) | 高い(大手メディア優位) | 非常に高い(Google E-E-A-T依存) |
| ユーザーの元記事遷移率 | 高い(ソースURLクリック率 約15〜25%) | 低い(引用クリック率 約5〜10%) | 中(表示のみでクリック率は低下傾向) |
| 最適化のキーポイント | PerplexityBot許可 + 鮮度 + 構造化 | GPTBot許可 + 権威性 + 一次データ | Google SEO基盤 + 構造化データ + E-E-A-T |
| robots.txt制御 | PerplexityBot で制御可能 | GPTBot / OAI-SearchBot で制御可能 | Google-Extended で制御可能 |
この比較表から読み取るべき3つのポイント:
- Perplexityは最も「民主的」なAI検索: ドメイン権威性がChatGPTやGoogle AI Overviewほど絶対的ではなく、専門性と鮮度で勝負できる
- Perplexityは最も「流入に直結する」AI検索: ソースURLクリック率が他と比べて高いため、引用=トラフィックに直結する
- 3つのAI検索に共通するコア施策は存在する: 結論ファースト・構造化・一次データの3点は全プラットフォームで有効
AI検索全体の構造と各最適化手法の位置関係については、SEO vs LLMO vs AIO の違いと使い分けで詳しく整理しています。
CITE-Pフレームワーク——Perplexityに引用される5要素
汎用LLMOでは C-CITEモデル を提唱しましたが、Perplexity特化の最適化には専用のフレームワークが必要です。ここでは CITE-P(サイト・ピー) を提案します。
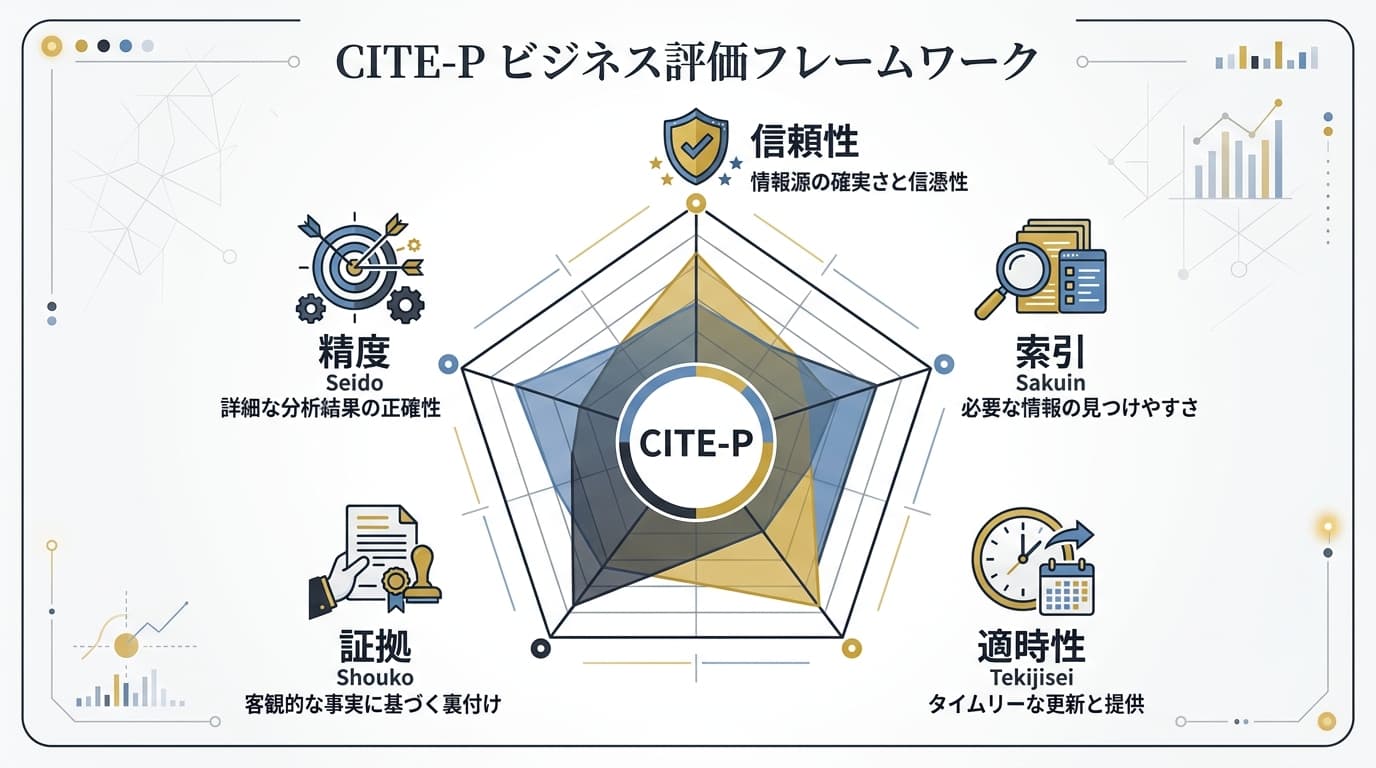
C: Credibility(信頼性)
Perplexityは回答の信頼性を担保するために、ソースの信頼性を重視します。具体的に効く施策は以下の通りです。
- 著者プロフィールの明示: 記事に著者名・肩書き・専門領域を明記する。著者ページ(Author Page)を作成し、JSON-LDの
Personスキーマでマークアップする - 運営元情報の充実: 会社概要・事業内容・実績をサイトに掲載し、
Organizationスキーマで構造化する - E-E-A-T シグナルの強化: 執筆者の経験(Experience)、専門性(Expertise)、権威性(Authoritativeness)、信頼性(Trustworthiness)を示す情報を記事内に含める
- 被リンクの質: 権威あるサイトからの被リンクはドメイン信頼性を高め、Perplexityの引用選択にも間接的に影響する
I: Index(インデックス確保)
PerplexityBotにクロールされなければ、引用は絶対に起きません。 この基本が見落とされがちです。
# robots.txt の推奨設定
User-agent: PerplexityBot
Allow: /
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Google-Extended
Allow: /加えて、以下の施策が必要です。
- Bingウェブマスターツールにサイトを登録: PerplexityはBing検索APIを利用しているため、Bingインデックスの有無が引用可否に直結する
- サイトマップの提出: Google Search Console と Bing Webmaster Tools の両方にXMLサイトマップを提出する
- llms.txt の設置(推奨): サイトルートに
llms.txtを配置し、AIクローラーに対してサイト構造・主要コンテンツ・更新頻度を伝える。Perplexityがllms.txtを直接読むかは公式には未確認だが、他のAI検索エンジンを含む総合対策として設置しておく価値がある
T: Timeliness(鮮度)
Perplexityの引用ロジックにおいて、鮮度は最も過小評価されている要因です。リアルタイム検索を前提とするPerplexityでは、情報の新しさが引用選択に直接影響します。
- 公開日と更新日を必ず明記:
datePublishedとdateModifiedを JSON-LD で構造化する。HTMLの<time>タグでも明示する - 年号キーワードをタイトルと見出しに含める: 「2026年版」「2026年最新」などの時間修飾は、Perplexityが鮮度を判断するシグナルになる
- 定期的な内容更新: 少なくとも四半期に1回、記事内の数値・事例・リンクを更新し、
dateModifiedを更新する - 速報性のある記事を積極的に公開: 新サービスのローンチ、業界ニュースに関する解説記事は、公開直後にPerplexityに引用されやすい
E: Evidence(一次データ・エビデンス)
Perplexityが他のソースよりも自社記事を選ぶ理由を作るのがエビデンスです。
- 独自調査データ: アンケート結果、実験データ、ベンチマーク測定値など、自社でしか取得できないデータ
- ケーススタディ: 実際のクライアント事例、社内実装事例を具体的な数値付きで記述
- 引用チェーン: 信頼性の高い外部ソース(論文、公的統計、企業IR)を出典として明記。Perplexityは「出典を明示しているソース」を信頼する傾向がある
- 具体的な数値: 「効果があった」ではなく「CVRが23%改善した」のように、検証可能な数値を示す
P: Precision(引用精度の設計)
最後の要素は、Perplexityが引用しやすい「粒度」でコンテンツを設計することです。
- 冒頭50字ルール: 記事の冒頭、または各セクションの冒頭に、50字前後の明確な定義文・結論文を置く。Perplexityはこの部分を引用テキストとして抽出しやすい
- FAQ構造: 「Xとは?」「Xの方法は?」のようなQ&A形式で構成されたコンテンツは、Perplexityのクエリ応答パターンに合致しやすい
- リスト・表の活用: 箇条書き、番号付きリスト、比較表は情報抽出の精度が高い
- JSON-LD 構造化データ:
FAQPage、HowTo、Articleスキーマの実装により、Perplexityのパーサーが記事の構造を正しく理解する助けになる - 1段落1論点: 複数の論点を1段落に詰め込まず、1段落に1つの主張を置く。Perplexityは段落単位で引用するため、論点が分離されているほうが引用精度が上がる
20項目の実践チェックリスト
CITE-Pフレームワークの5要素を、現場で即使える20項目のチェックリストに落とし込みます。優先度(高・中・低)付きです。
Credibility(信頼性):4項目
| # | チェック項目 | 優先度 | 確認方法 |
|---|---|---|---|
| 1 | 記事に著者名・肩書き・専門領域が明記されているか | 高 | 記事ページを目視確認 |
| 2 | 著者ページが存在し、Person スキーマでマークアップされているか | 中 | Schema.org Validatorで確認 |
| 3 | 会社概要ページに Organization スキーマが実装されているか | 中 | 構造化データテストツールで確認 |
| 4 | 記事内に執筆者の経験・実績に基づく記述があるか(E-E-A-T の Experience) | 高 | 記事内に「自社で検証した結果」等の実体験記述の有無を確認 |
Index(インデックス確保):4項目
| # | チェック項目 | 優先度 | 確認方法 |
|---|---|---|---|
| 5 | robots.txt で PerplexityBot を Allow しているか | 高 | https://自社ドメイン/robots.txt を直接確認 |
| 6 | Bing Webmaster Tools にサイトが登録・インデックスされているか | 高 | Bing Webmaster Tools のダッシュボード |
| 7 | XMLサイトマップが Google / Bing の両方に提出されているか | 中 | 各ウェブマスターツールで確認 |
| 8 | llms.txt をサイトルートに配置しているか | 低 | https://自社ドメイン/llms.txt にアクセスして確認 |
Timeliness(鮮度):4項目
| # | チェック項目 | 優先度 | 確認方法 |
|---|---|---|---|
| 9 | 記事に公開日(datePublished)と更新日(dateModified)がJSON-LDで記述されているか | 高 | 構造化データテストツールで確認 |
| 10 | タイトルまたはH1に年号(例: 2026年版)が含まれているか | 中 | 記事のタイトルタグを確認 |
| 11 | 過去3ヶ月以内に記事内容を更新しているか | 高 | CMS の更新日を確認 |
| 12 | 業界ニュースやトレンド変化に対応した速報記事を月1本以上出しているか | 中 | 公開記事の日付を確認 |
Evidence(エビデンス):4項目
| # | チェック項目 | 優先度 | 確認方法 |
|---|---|---|---|
| 13 | 記事内に独自調査データ・実験結果・ベンチマーク等の一次情報があるか | 高 | 記事内の「独自調査」「自社調べ」「検証結果」等を検索 |
| 14 | 具体的な数値(%, 件数, 金額等)が3箇所以上含まれているか | 中 | 数値の出現箇所をカウント |
| 15 | 外部出典(論文, 公的統計, 企業IR等)が明示されているか | 中 | 出典リンク・引用表記の有無を確認 |
| 16 | ケーススタディまたは実装事例が1件以上含まれているか | 高 | 事例セクションの有無を確認 |
Precision(引用精度の設計):4項目
| # | チェック項目 | 優先度 | 確認方法 |
|---|---|---|---|
| 17 | 記事冒頭50字以内に明確な定義文または結論文があるか | 高 | 記事の1段落目を確認 |
| 18 | FAQPage / HowTo / Article の構造化データが実装されているか | 高 | 構造化データテストツールで確認 |
| 19 | 比較表・リスト・箇条書きが適切に使われているか | 中 | 記事のHTML構造を確認 |
| 20 | 1段落が1論点で構成されているか(150字以下が目安) | 中 | 段落の文字数と論点数を確認 |
チェックリストの使い方
- まず優先度「高」の10項目を通す: 1・4・5・6・9・11・13・16・17・18 の10項目が最優先。これだけで引用率の基盤が整う
- 次に優先度「中」の8項目: 2・3・7・10・12・14・15・19 を順次対応
- 最後に優先度「低」の2項目: 8・20 は余力があれば
- 四半期ごとに全20項目を再チェック: Perplexityのアルゴリズムは進化するため、定期的な再評価が必要
業種別のPerplexity最適化事例
CITE-Pフレームワークの適用方法は業種によって異なります。ここでは5つの業種について、特に効く施策と実際の引用パターンを解説します。
1. SaaS / IT企業
特に効く施策: Evidence(一次データ)+ Precision(構造化)
SaaS企業は自社プロダクトの技術仕様、ベンチマーク、導入事例を一次データとして持っています。これをPerplexity最適化に活かす方法は以下の通りです。
- 比較表を充実させる: 「Aツール vs Bツール」のクエリに対して、Perplexityは比較表を含むページを優先的に引用する。料金・機能・制限を網羅した比較表を作成する
- APIドキュメントの最適化: 技術者がPerplexityで「Xの実装方法」を調べるケースが増加。APIドキュメントにも冒頭定義文と構造化データを実装する
- リリースノートのSEO化: 新機能のリリースノートは速報性が高く、Perplexityに引用されやすい。リリースノートにも見出し構造・日付・概要文を整備する
2. 士業(弁護士・税理士・社労士)
特に効く施策: Credibility(信頼性)+ Timeliness(鮮度)
士業は「資格」という圧倒的な信頼シグナルを持っています。
- 資格・登録番号を著者プロフィールに記載: 弁護士登録番号、税理士登録番号などを明記すると、Perplexityの信頼性判断に寄与する
- 法改正への速報対応: 法律・税制の改正時に速報解説記事を出すと、Perplexityの鮮度重視ロジックに刺さる。「2026年4月 労働基準法 改正」のようなクエリで引用されやすい
- 判例・通達の要約を作成: 判例や通達の概要を構造化して公開すると、Perplexityが法的質問の回答ソースとして引用する
3. EC / D2C
特に効く施策: Evidence(レビュー・比較データ)+ Precision(FAQ)
EC・D2Cでは「商品比較」「口コミ」「使い方」のクエリでPerplexityに引用されることが流入に直結します。
- 商品比較コンテンツの作成: 自社商品と競合商品の客観的な比較記事を作成する。スペック表、価格比較、ユーザーレビュー集計を含める
- FAQ ページの拡充: 「Xの洗い方」「Xのサイズ選び」など、購入後の質問にも答えるFAQを
FAQPageスキーマ付きで作成 - 成分・素材の詳細情報: 食品・化粧品・アパレルなど、成分や素材の詳細な説明は一次データとしてPerplexityに引用されやすい
4. メディア / オウンドメディア
特に効く施策: Timeliness(鮮度)+ Index(インデックス確保)
メディアはコンテンツ量が強みですが、Perplexityに引用されるには鮮度とインデックスの管理が鍵です。
- 更新日の管理を徹底: 古い記事でも内容更新すれば
dateModifiedを書き換え、鮮度シグナルを維持する - カテゴリ・タグの構造化: 記事カテゴリとタグを
BreadcrumbListスキーマで構造化し、Perplexityがサイト構造を理解しやすくする - 引用されやすいフォーマットの標準化: すべての記事で「冒頭50字定義→本文→まとめ→FAQ」のフォーマットを統一し、Perplexity引用の再現性を高める
5. 製造業 / BtoB
特に効く施策: Evidence(技術仕様・カタログ)+ Credibility(業界実績)
製造業はWebマーケティングが後発でも、Perplexity対策では技術仕様という圧倒的な一次データを持っています。
- 製品仕様書のWeb公開: PDFだけでなく、HTMLページとしても製品仕様を公開する。Perplexityはプレーンテキストを優先的にクロールする
- 技術コラムの定期発信: 「Xの原理」「Yの選び方」といった技術解説コンテンツを月1〜2本発信する
- 導入実績の数値化: 「導入企業500社以上」「稼働率99.7%」など、実績を具体的な数値で示す
効果測定方法——Perplexity引用をどうトラッキングするか
対策を実施したら、効果を測定する仕組みが必要です。2026年4月時点で使える測定方法を3つの階層で整理します。
第1階層: 手動モニタリング(最も確実)
週次で10〜20の主要キーワードをPerplexityに入力し、自社ドメインが引用されているかを記録します。 地味ですが、2026年時点では最も正確な方法です。
記録テンプレート:
| クエリ | 検索日 | Perplexity引用有無 | 引用順位(何番目のソース) | 引用されたURL | 備考 |
|---|---|---|---|---|---|
| (キーワード) | 2026-04-06 | あり/なし | [3] | /posts/xxx | — |
ポイント:
- 同じクエリでも日によって引用ソースが変動するため、週次で定点観測する
- Pro版とFree版で結果が異なることがあるため、可能であれば両方で確認する
- Deep Researchモードでは引用数が増えるため、通常検索とは分けて記録する
第2階層: アクセス解析での流入計測
Google Analytics 4(GA4)やサーバーログで、Perplexityからの流入を計測します。
- GA4でのリファラー確認:
perplexity.aiからの流入をリファラーレポートで抽出する。ランディングページごとの流入数から、どの記事がPerplexityに引用されてトラフィックを生んでいるかがわかる - サーバーログでのクローラー確認: PerplexityBot のアクセスログを分析し、クロール頻度・対象ページを把握する。クロール頻度が高いページは引用候補に入りやすい
第3階層: 外部ツールの活用
2026年時点で利用できるツールと、その限界を整理します。
| ツール名 | 機能 | 限界 |
|---|---|---|
| Ahrefs(Brand Radar) | AI検索での自社ブランド言及をトラッキング | Perplexity個別の引用追跡は限定的 |
| BrightEdge(GEO Analytics) | AI検索全般での引用状況を可視化 | エンタープライズ向け(高額) |
| Semrush(AI Visibility) | AI検索での可視性スコアを算出 | Perplexity特化の深い分析は未対応 |
| 自社スクリプト(API利用) | Perplexity APIで自社キーワードを定期検索 | APIコスト・利用規約の確認が必要 |
現実的な推奨: まず第1階層の手動モニタリングと第2階層のGA4流入計測を始め、月次レポートとして定着させる。外部ツールの導入は予算と規模に応じて検討する。
まとめ——Perplexity対策は「引用される設計」の最前線
Perplexity SEO対策の要点を3つに集約します。
- Perplexityは「リアルタイム×ソース明示」のAI検索: 引用=流入に直結する唯一のAI検索エンジンであり、対策のROIが最も可視化しやすい
- CITE-Pフレームワークの5要素を網羅する: Credibility(信頼性)・Index(インデックス)・Timeliness(鮮度)・Evidence(エビデンス)・Precision(引用精度)の5要素を全て押さえることで、引用率を最大化できる
- 20項目チェックリストで即実装する: 優先度「高」の10項目を先に対応するだけで、多くの競合サイトに対して優位に立てる
Perplexity対策は、LLMO対策の中でも最も即効性が高く、効果が測定しやすい領域です。Google AI Overviewの引用は制御しにくく、ChatGPTの引用は学習タイミング依存ですが、Perplexityはリアルタイムクロールのため今日の改善が明日の引用に反映される可能性があります。
まずは20項目チェックリストの優先度「高」から着手してください。AI検索時代の包括的な戦略は SEO vs LLMO vs AIO の全体像 で、GEO(Generative Engine Optimization)の観点からの追加施策は GEO対策ガイド で解説しています。

この記事の著者
Agentic Base 編集部
AIエージェントとWebメディア運用の知見を活かし、実践的なナレッジを発信しています。



