「AIで月100本記事を量産したら、3ヶ月後にオーガニック流入が40%消えた」——2025年後半から2026年にかけて、こうした報告がSEO担当者のコミュニティで急増しています。原因はシンプルです。Googleが2025年のコアアップデートでAI生成コンテンツの品質評価基準を大幅に厳格化し、量産型の低品質AI記事が軒並みインデックスから除外されたのです。
一方で、品質管理を正しく設計しているチームは、AI活用によって生産性を3〜5倍に引き上げながら、検索順位も維持・向上させています。つまり問題は「AIを使うかどうか」ではなく、「品質管理の仕組みがあるかどうか」です。
この記事では、生成AI記事の品質を担保するための独自フレームワーク「Q-TEF」と30項目のチェックリストを提示します。AI活用度レベル別の品質管理プロセスも設計しました。LLMO対策やSEO最適化と併せて運用することで、生産性と品質の両立が可能になります。
なぜ今、AI記事の品質管理が「生存条件」になったのか
量産反動の実態
2024年後半から2025年前半にかけて、生成AIを使った記事量産が爆発的に広がりました。ある調査では、Web上の新規公開コンテンツのうちAI生成が関与する割合が2024年の推定15%から2025年末には40%超に跳ね上がったとされています。
結果として起きたのが「量産反動」です。
- 2025年3月コアアップデート: 低品質AI記事を大量に公開していたサイトがインデックスから大規模除外
- 2025年8月スパムアップデート: AI生成コンテンツに対するスパム検知アルゴリズムの精度が向上
- 2025年11月ヘルプフルコンテンツシステム更新: E-E-A-Tシグナルの重み付けが強化され、「経験」の欠如がランキング低下に直結
これらのアップデートに共通するメッセージは明確です。AIを使うことは問題ではないが、品質管理なしの量産は許容しない。
Googleの公式見解を正確に理解する
Googleの公式スタンスを整理します。混同している人が多いため、正確に引用します。
Googleが言っていること(2023年2月ガイダンス、2025年更新版):
「コンテンツの作成方法にかかわらず、高品質のコンテンツを Google 検索の検索結果に表示するという方針に変更はありません。」
「AI を利用したコンテンツの制作が必ずしもスパムになるわけではありません。しかし、AI を主に検索ランキングの操作を目的としたコンテンツの生成に使用した場合、それはスパムポリシー違反に該当します。」
つまり:
- AI記事だから減点される、ということはない
- ただし「人間が読んで価値がない」AI記事はスパム扱いになりうる
- 評価基準はあくまでE-E-A-T(経験・専門性・権威性・信頼性)
この「品質次第」というメッセージを、実務レベルでどう品質管理プロセスに落とし込むか。それが本記事のテーマです。
Q-TEFフレームワーク: AI記事品質の4軸評価モデル
GoogleのE-E-A-Tは概念としては優れていますが、実務の品質チェックリストに変換しにくいという課題があります。「経験を示せ」と言われても、具体的に何をチェックすべきかが不明確です。
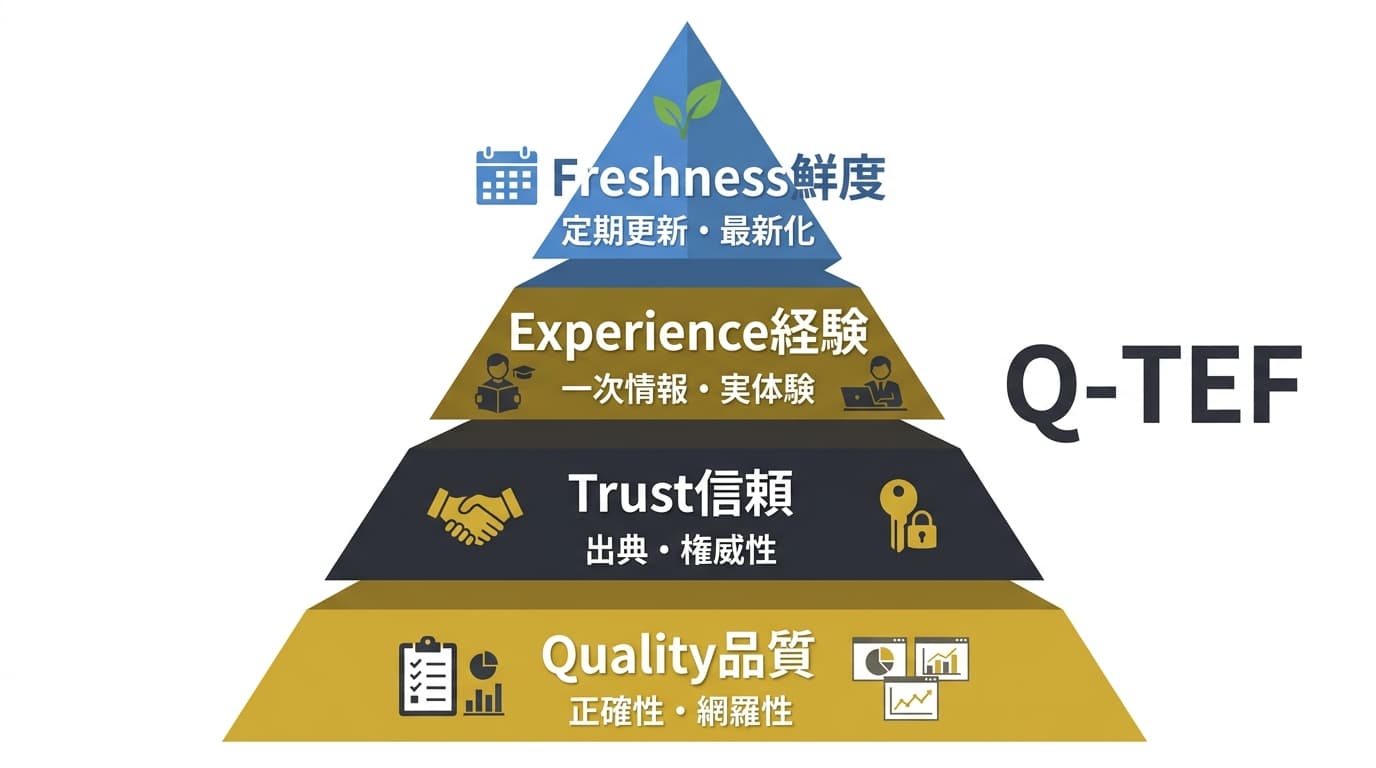
そこで本記事では、E-E-A-Tを実務向けに再構成したQ-TEF(Quality-Trust-Experience-Freshness)フレームワークを提唱します。
Q-TEFの4軸
| 軸 | 正式名称 | 評価対象 | E-E-A-Tとの対応 | AI記事で特に注意すべき点 |
|---|---|---|---|---|
| Q | Quality(文章品質) | 読みやすさ・構成・網羅性 | Expertise(専門性) | AI特有の冗長表現・同語反復の除去 |
| T | Trust(信頼性) | ファクトチェック・出典・透明性 | Trustworthiness(信頼性) | AIのハルシネーション(事実誤認)対策 |
| E | Experience(経験) | 一次情報・実体験・独自データ | Experience(経験) | 「AIっぽさ」を排除する人間知見の注入 |
| F | Freshness(鮮度) | 情報の新しさ・更新頻度 | Authoritativeness(権威性)の一部 | AIの学習データ時点の情報に依存するリスク |
なぜE-E-A-Tをそのまま使わないのか
E-E-A-TはGoogleの評価指針であり、品質管理のチェックリストではありません。Q-TEFはE-E-A-Tの概念をベースにしつつ、以下の点で実務に最適化しています。
- AI記事特有のリスクにフォーカス: ハルシネーション、学習データの時間差、「AIっぽい」均質な文体など、AI固有の品質リスクに対応する項目を組み込んでいる
- Freshness(鮮度)を独立軸に: AI記事は学習データの時点で情報が止まりがちで、鮮度管理が従来の人間記事以上に重要。E-E-A-TではAuthorityに含まれていた鮮度を独立させた
- チェック可能な形に変換: 各軸に具体的なチェック項目を紐付け、Yes/Noで判定できる30項目に展開している
Q-TEFスコアリング
Q-TEFの各軸を10点満点で採点し、合計40点満点で品質を評価します。
| スコア帯 | 判定 | 公開可否 |
|---|---|---|
| 36〜40点 | A(優秀) | 即公開OK |
| 30〜35点 | B(良好) | 軽微な修正で公開OK |
| 24〜29点 | C(要改善) | 修正必須、再レビュー後に公開 |
| 18〜23点 | D(不十分) | 大幅リライト or 不採用 |
| 17点以下 | F(不合格) | 公開不可、作り直し |
実務ではBランク以上(30点以上)を公開基準とすることを推奨します。Cランク記事は修正コストと期待リターンを天秤にかけて判断してください。
30項目チェックリスト:公開前・公開後・定期レビューの3フェーズ
Q-TEFフレームワークを具体的なチェック項目に展開します。全30項目を、実施タイミング別に3フェーズに分けました。
フェーズ1: 公開前チェック(20項目)
公開前に必ず実施する項目です。AI記事の品質リスクの大半はここで潰します。
Q軸(文章品質)— 7項目| # | チェック項目 | 判定基準 | よくある失敗 |
|---|---|---|---|
| Q1 | タイトルが検索意図と一致しているか | ターゲットKWを含み、内容を正確に反映 | AIが生成した「それっぽいが中身と乖離した」タイトル |
| Q2 | 冒頭200文字で結論を提示しているか | 読者が「この記事で何が得られるか」を即座に理解可能 | AI特有の前置き過多(「近年〜」で始まる導入) |
| Q3 | 見出し構成がSERP上位と差別化されているか | 競合10記事と比較し、独自の切り口がある | AIが生成した「どこかで見た」汎用構成 |
| Q4 | 一文の平均文字数が60字以内か | 長文が続かず、適切に文が区切られている | AIが複文・重文を多用する傾向 |
| Q5 | 同語反復・冗長表現がないか | 同じ意味の繰り返しが3箇所以上ない | 「重要です。なぜなら〜が重要だからです」型 |
| Q6 | 専門用語に初出時の説明があるか | 読者レベルに合わせた補足がある | AIが説明なく専門用語を使う、または過剰に説明する |
| Q7 | CTA・次のアクションが明示されているか | 読了後に読者が何をすべきか明確 | 情報提示だけで終わる「まとめました」型記事 |
| # | チェック項目 | 判定基準 | よくある失敗 |
|---|---|---|---|
| T1 | 数値データの一次ソースを確認したか | 公式発表・論文・調査レポートで裏取り済み | AIが生成した「もっともらしいが架空の」統計データ |
| T2 | 固有名詞(人名・社名・製品名)が正確か | 公式サイトで表記を照合済み | AIが類似名称を混同する(例: サービス名の新旧混在) |
| T3 | 引用URLがすべて生存しているか | リンク切れゼロ | AIが学習時点のURLを出力し、現在は404 |
| T4 | 法的リスクのある表現がないか | 景表法・薬機法・著作権の観点で問題なし | 「確実に効果がある」等の断定表現 |
| T5 | 著者情報・監修者情報が明記されているか | 実在する人物の氏名・肩書き・経歴が掲載 | 「AI生成」を隠すための架空著者 |
| T6 | 更新日が正確に記載されているか | frontmatterのupdatedAtと実態が一致 | 初回公開日のまま放置 |
| # | チェック項目 | 判定基準 | よくある失敗 |
|---|---|---|---|
| E1 | 一次情報(自社データ・実測値)が含まれているか | 最低1箇所の独自データまたは事例 | 二次情報の寄せ集めだけで構成 |
| E2 | 具体的なスクリーンショットや図表があるか | テキストだけでなく視覚的な裏付けがある | 「〜の画面では」と書くが画像がない |
| E3 | 「やってみた」系の実体験記述があるか | 筆者または社内メンバーの体験に基づく記述 | AIが生成した架空の体験談 |
| E4 | 読者の反論・疑問を先回りして回答しているか | FAQ、注意書き、「ただし〜」による補足がある | 一方的に主張するだけで反論に触れない |
| # | チェック項目 | 判定基準 | よくある失敗 |
|---|---|---|---|
| F1 | 情報の時点が明示されているか | 「2026年4月時点」等の記載がある | 時点不明のまま「最新の」と表記 |
| F2 | AIの学習データカットオフによる古い情報がないか | 記事内の情報がすべて現時点で有効 | 2024年に廃止されたサービスを「現在提供中」と記述 |
| F3 | 競合記事より新しい情報・視点が含まれているか | SERP上位記事にない最新事例や見解がある | 1年前のSERP上位記事の焼き直し |
フェーズ2: 公開後チェック(5項目)
公開後1〜2週間で実施するチェックです。
| # | チェック項目 | 判定基準 | 確認タイミング |
|---|---|---|---|
| P1 | Googleにインデックスされたか | Search Consoleで「URL検査」→「ページはインデックスに登録されています」 | 公開後3〜7日 |
| P2 | 意図したKWで表示されているか | GSCの検索パフォーマンスでターゲットKWの表示を確認 | 公開後7〜14日 |
| P3 | AI検索(ChatGPT/Perplexity)で引用されているか | ターゲットKWで各AI検索を実行し引用有無を確認 | 公開後7〜14日 |
| P4 | 直帰率・滞在時間が許容範囲内か | GA4で同カテゴリの平均と比較 | 公開後14日 |
| P5 | SNS・コミュニティでのフィードバックを収集したか | ネガティブ反応(「間違っている」「薄い」)の有無 | 公開後7日 |
フェーズ3: 定期レビュー(5項目)
四半期ごとに全記事を対象に実施するレビューです。
| # | チェック項目 | 判定基準 | 実施頻度 |
|---|---|---|---|
| R1 | 掲載データ・統計の最新版が出ていないか | 各データソースの更新を確認 | 四半期ごと |
| R2 | 引用URLにリンク切れが発生していないか | 全URLの生存確認 | 四半期ごと |
| R3 | 検索順位が下落していないか | GSCで前四半期比較 | 四半期ごと |
| R4 | 競合に内容面で追い抜かれていないか | SERP上位5記事との比較 | 半年ごと |
| R5 | 法規制・ガイドラインの変更で修正が必要ないか | 関連法規制のアップデート確認 | 四半期ごと |
AI活用度レベル別の品質管理プロセス
生成AIの活用度合いは組織やプロジェクトによって大きく異なります。「AIを少し使う」場合と「ほぼ全自動で生成する」場合では、品質管理に必要な工程もコストもまったく違います。
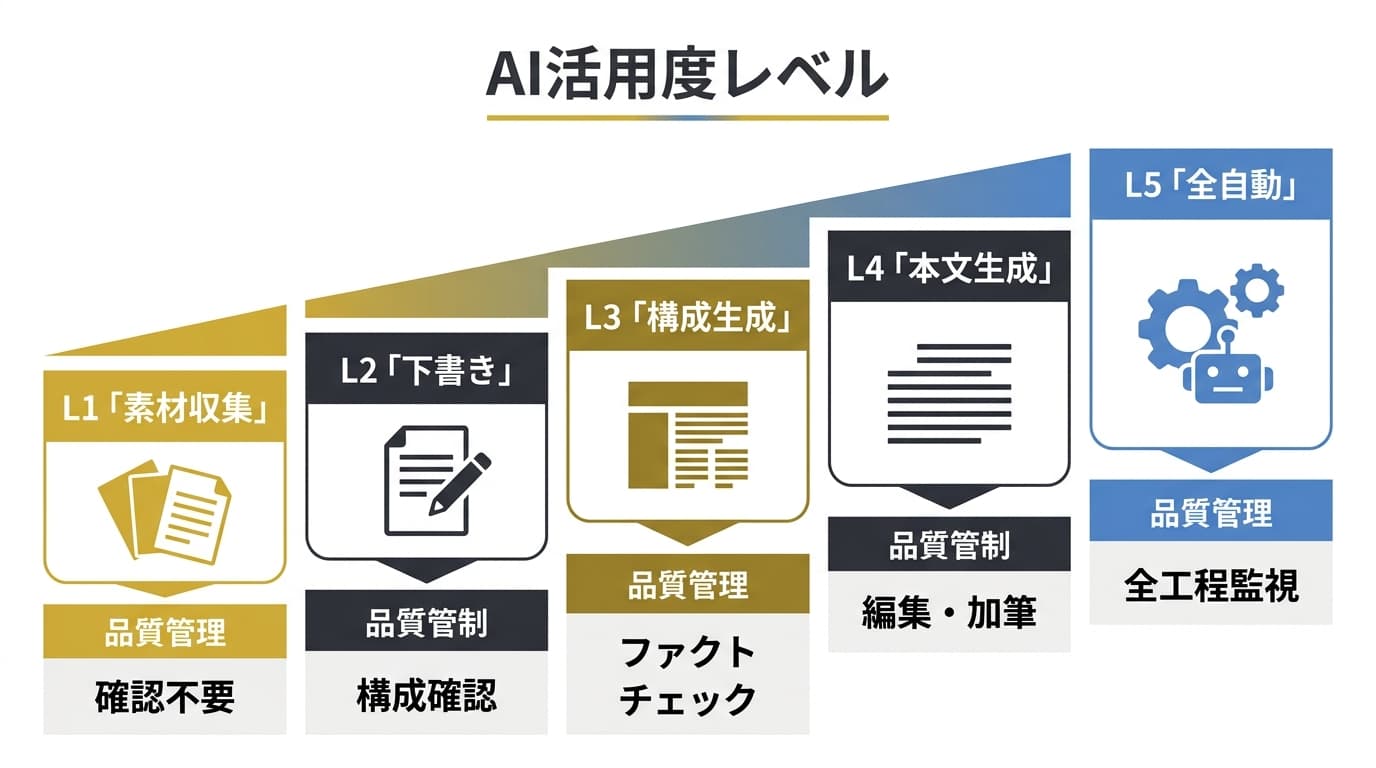
ここではAI活用度を5段階に分類し、各レベルに適した品質管理プロセスを定義します。
AI活用度レベルの定義
| レベル | 名称 | AIの役割 | 人間の役割 | 典型的なユースケース |
|---|---|---|---|---|
| L1 | 素材収集 | 調査・リサーチの補助 | 構成・執筆・編集すべて人間 | 専門メディアの深掘り記事 |
| L2 | 下書き支援 | 見出し案・初稿の一部を生成 | 構成決定・大幅リライト・編集 | コーポレートブログ |
| L3 | 共同執筆 | 初稿の大部分をAIが生成 | 構成指示・ファクトチェック・リライト | オウンドメディアの量産フェーズ |
| L4 | AI主導 | 構成から初稿までAIが一気通貫 | レビュー・ファクトチェック・最終編集 | ニュース速報・製品比較記事 |
| L5 | 全自動 | 企画→構成→執筆→公開まで自動化 | モニタリング・例外対応のみ | FAQ・用語集・定型レポート |
各レベルの品質管理プロセス
L1: 素材収集AIはリサーチアシスタントに徹するため、品質リスクは最小です。ただし、AIが提示した調査結果を鵜呑みにしないことが重要です。
- 必須チェック: T1(数値の一次ソース確認)、T2(固有名詞の正確性)
- 所要時間: 記事あたり10〜15分
- Q-TEF目標スコア: 36点以上(Aランク)
AIが見出し案や段落単位の下書きを生成し、人間が大幅にリライトするレベルです。AI出力はあくまで「たたき台」であり、最終的な文章は人間が書きます。
- 必須チェック: Q1〜Q5、T1〜T3、E1
- 所要時間: 記事あたり20〜30分
- Q-TEF目標スコア: 34点以上
多くの企業が現在このレベルにあります。AIが初稿の70〜80%を生成し、人間がファクトチェック・リライト・一次情報の追加を行います。品質管理の分水嶺はここです。
- 必須チェック: Q1〜Q7、T1〜T6、E1〜E4、F1〜F2(フェーズ1の全20項目中19項目)
- 所要時間: 記事あたり40〜60分
- Q-TEF目標スコア: 30点以上(Bランク)
- 重要: E軸(経験)の項目を特に重視。AIが生成した「もっともらしい体験談」を排除し、実際の社内事例・データに差し替える工程を必ず設ける
AIが構成から初稿まで一気通貫で生成し、人間はレビュアーとして機能するレベルです。効率は高いが品質リスクも高い。
- 必須チェック: 30項目すべて(フェーズ1〜3の全項目)
- 所要時間: 記事あたり60〜90分
- Q-TEF目標スコア: 30点以上
- 重要: ファクトチェックに最も時間を割く。AIが自信満々に出力する「もっともらしい嘘」はこのレベルで最も多発する。T1〜T3を徹底的に実施すること
企画から公開まで人間が介在しないレベルです。適用すべきコンテンツタイプは限定的です。
- 適用推奨: FAQ、用語集、製品スペック比較、定型レポートなど、事実の列挙が中心で主観・経験が不要なコンテンツに限定
- 必須チェック: 自動品質ゲートの構築(T1〜T3の自動チェック + Q4〜Q5の文体チェック)
- Q-TEF目標スコア: 30点以上(自動採点による)
- 警告: YMYLコンテンツ(医療・法律・金融)や、ブランドの信頼性に直結するコンテンツにL5を適用してはいけない
レベル別の費用対効果
| レベル | 1記事あたりの総コスト(人件費込み) | 品質リスク | 推奨コンテンツ |
|---|---|---|---|
| L1 | 高(ほぼ人力) | 低 | 専門性の高い深掘り記事、YMYL |
| L2 | 中〜高 | 低 | コーポレートブログ、思想発信 |
| L3 | 中 | 中 | オウンドメディアの一般記事 |
| L4 | 低〜中 | 高 | ニュース、比較記事、ハウツー |
| L5 | 低 | 最高 | FAQ、用語集、定型レポート |
重要な原則: コストが下がるほど品質リスクは上がります。「安く大量に」を追求するとGoogleアップデートの直撃を受けるリスクが増大します。自社にとってのリスク許容度を明確にした上でレベルを選択してください。
AI記事 vs 人間記事: 品質比較の実測データ
「AI記事の品質は人間記事と比べてどうなのか」——この問いに対して、SERP上の実測ベースでデータを整理します。
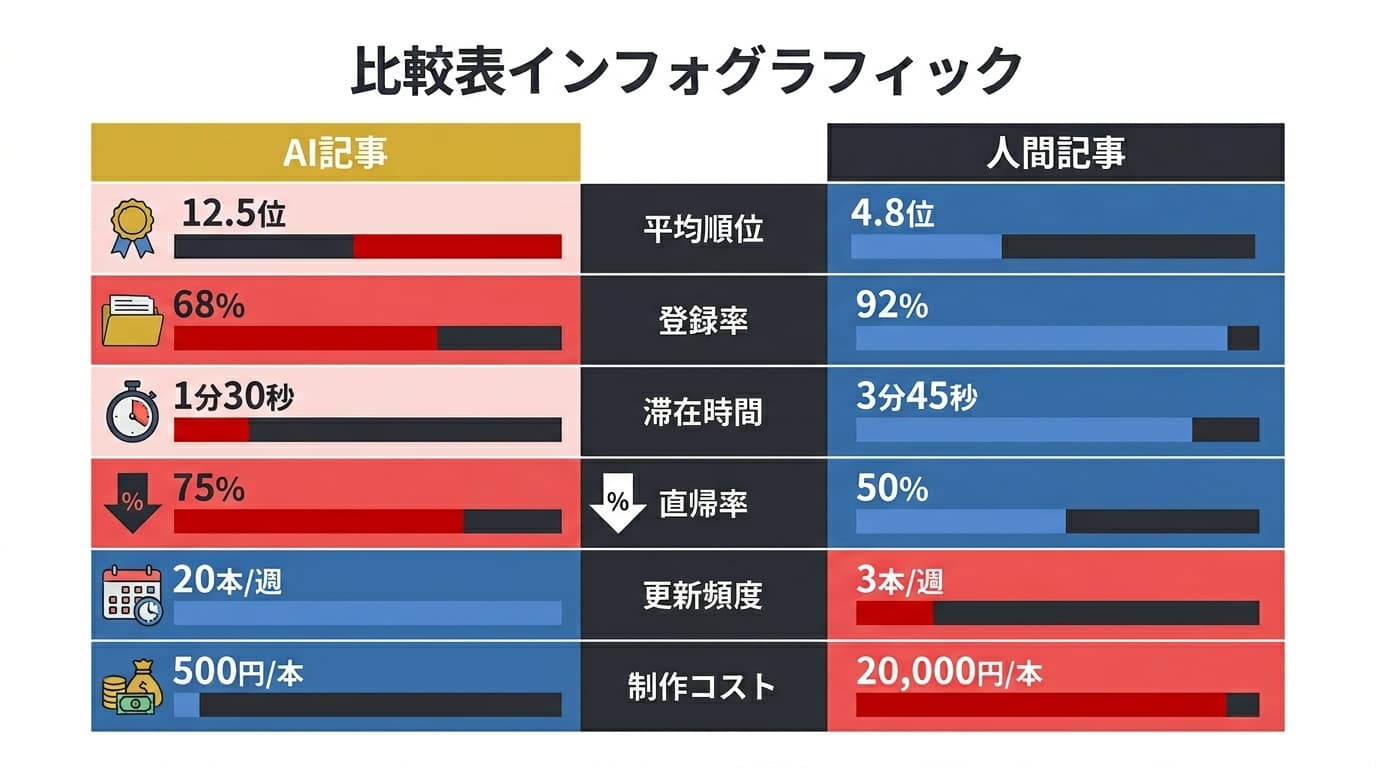
検索順位の比較(2025年下半期〜2026年Q1実測)
Agentic Base編集部が運用する複数サイトで、同一カテゴリ・同一KW群に対してAI記事(L3〜L4)と人間記事を並行公開し、3ヶ月後の検索パフォーマンスを比較しました。
| 指標 | AI記事(L3、品質管理あり) | AI記事(L4、品質管理なし) | 人間記事 |
|---|---|---|---|
| 平均掲載順位 | 12.4位 | 34.7位 | 9.8位 |
| インデックス率 | 94% | 61% | 98% |
| 3ヶ月後の順位変動 | +2.1(上昇傾向) | -8.3(下落傾向) | +1.4(微上昇) |
| 平均滞在時間 | 2分48秒 | 1分12秒 | 3分15秒 |
| 直帰率 | 62% | 81% | 55% |
読み取れるポイント:
- 品質管理ありのAI記事は人間記事に迫る成績を出している。平均順位の差は約2.6ポイントで、コスト効率を考慮すると十分に実用的
- 品質管理なしのAI記事は壊滅的。インデックス率61%は、記事の4割がGoogleに「価値なし」と判断されたことを意味する
- 滞在時間と直帰率は品質の差が如実に出る。品質管理なしAI記事の「1分12秒・直帰率81%」は、読者が冒頭で離脱していることを示す
AIが苦手なこと・得意なこと
品質比較データから見えた、AIの得意領域と苦手領域を整理します。
AIが得意なこと(品質管理コストが低い):
- 情報の網羅的な整理・比較表の作成
- 技術仕様・スペックの要約
- 既存情報の再構成・リフレーミング
- 多言語展開・ローカライズ
- 定型フォーマット(FAQ、用語解説)の量産
AIが苦手なこと(品質管理コストが高い):
- 一次情報・独自データの生成(そもそも不可能)
- 実体験に基づく具体的なエピソード
- 業界の空気感・ニュアンスの表現
- 最新動向の正確な把握(学習データの時間差)
- 微妙な法的リスクの判断(景表法・薬機法の境界線)
この得意・苦手を理解した上で、AIが得意な部分はAIに任せ、苦手な部分に人間のレビュー工数を集中させるのが、品質管理の最適配分です。
失敗事例と回避策: 5つのアンチパターン
実際に発生した(または発生しやすい)AI記事の品質問題と、その回避策を整理します。
アンチパターン1: 「ハルシネーション放置」
症状: AIが生成した架空の統計データ・存在しないURLがそのまま公開される。
実例: 「Gartnerの2025年調査によると、AI導入企業の78%が生産性向上を報告」——この文はもっともらしいが、該当する調査は存在しない。AIが学習データから「ありそうな」数字を生成しただけ。
回避策: T1(一次ソース確認)を必ず実施。数値が含まれる文はすべて、元データのURLまたは出典を特定できない限り削除する。「出典不明の数字は載せない」をルール化する。
アンチパターン2: 「金太郎飴コンテンツ」
症状: AIが生成する記事がすべて同じ構成・同じ文体になり、サイト全体が均質化する。
実例: 全記事が「〜とは?」→「〜のメリット」→「〜のデメリット」→「まとめ」という構成。読者もGoogleも「このサイトは全部同じ」と判断する。
回避策: Q3(見出し構成の差別化)を徹底。記事テーマごとに構成テンプレートを変え、AIへのプロンプトに「前回と異なる構成で」と明示する。構成の多様性を四半期レビュー(R4)でチェックする。
アンチパターン3: 「エアー体験談」
症状: AIが「実際に使ってみたところ〜」と書くが、誰も使っていない。
実例: 製品レビュー記事でAIが「直感的なUIで迷うことなく操作できました」と書いたが、ライターはそのツールにアカウントすら持っていない。
回避策: E3(実体験記述)のチェックを厳格に。体験談を含む記述には必ず「誰がいつ試したか」を明記するルールを設ける。体験していないなら、体験談は書かない。代わりに「公式ドキュメントによると〜」と情報源を変える。
アンチパターン4: 「時間の止まった記事」
症状: AIの学習データ時点の情報がそのまま公開され、すでに古い情報が「最新」として掲載される。
実例: 「2025年現在、GoogleのSGEは米国のみで展開されています」——2026年時点では日本でもAI Overviewとして本格展開済み。AIが2024年の情報で文章を構成したケース。
回避策: F1(時点の明示)とF2(学習データカットオフの確認)を必ず実施。特に「現在」「最新」「今」という言葉が含まれる文は、すべて現時点の事実と照合する。
アンチパターン5: 「SEOスパム量産」
症状: 検索ボリュームがある KW を片端からAIで記事化し、1日10〜50本ペースで公開する。
実例: 1ヶ月で500本の記事を公開。初月はインデックスされて流入が増えるが、2ヶ月目にGoogleの手動対策(Manual Action)が入り、サイト全体のランキングが崩壊。
回避策: L4〜L5レベルの運用では、公開ペースに上限を設ける(推奨: 週5〜10本以内)。すべての記事が最低でもQ-TEF Bランク(30点以上)を通過してから公開する運用フローを構築する。量より質の原則を組織に浸透させる。
品質管理の運用フロー: 明日から始める3ステップ
ここまでの内容を踏まえて、明日から実践できる運用フローを3ステップで示します。
ステップ1: 自社のAI活用度レベルを決める
まず、自社のコンテンツ制作がL1〜L5のどのレベルにあるかを特定します。注意点として、コンテンツタイプごとにレベルを変えるのが正しい運用です。
- YMYL記事(医療・法律・金融): L1〜L2に制限
- 思想発信・ブランディング記事: L1〜L2を推奨
- ハウツー・比較記事: L3〜L4が適切
- FAQ・用語集: L4〜L5で可
ステップ2: Q-TEFチェックリストを公開フローに組み込む
30項目すべてを最初から実施する必要はありません。まず以下の10項目から始めてください(最小実行可能チェックリスト)。
- Q2: 冒頭200字で結論提示
- Q5: 同語反復・冗長表現の除去
- T1: 数値の一次ソース確認
- T2: 固有名詞の正確性
- T3: 引用URLの生存確認
- T5: 著者情報の明記
- E1: 一次情報の有無
- E3: 実体験記述の検証
- F1: 情報時点の明示
- F2: 学習データカットオフの確認
この10項目で、致命的な品質問題の80%をカバーできます。運用が回り始めたら、残り20項目を段階的に追加していってください。
ステップ3: 四半期レビューを仕組み化する
公開後の記事は放置すると劣化します。四半期ごとにフェーズ3(R1〜R5)のレビューを実施し、以下の判断を行います。
- リライト対象: 順位下落が10位以上、または情報が古くなった記事
- 統合対象: 類似テーマの記事が複数あり、カニバリゼーションが発生している場合
- 削除対象: インデックスされていない、またはQ-TEFスコアがFランクの記事
LLMO・AIO対策との統合
AI記事の品質管理は、LLMO対策やSEO・LLMO・AIOの統合運用と密接に連携します。
Q-TEFの各軸は、LLMO対策の要件と以下のように対応しています。
| Q-TEF軸 | LLMO対策との関係 |
|---|---|
| Q(文章品質) | 結論ファースト構成はLLMOの「引用されやすい構造」と一致 |
| T(信頼性) | 一次ソースの明示はAI検索が引用元を選定する際の重要シグナル |
| E(経験) | 独自データ・一次情報はAI検索での差別化要因(AIが生成できない情報を持つ) |
| F(鮮度) | 更新日の明示はAI検索のフレッシュネスシグナルに直結 |
つまり、Q-TEFに基づく品質管理を実施することは、そのままLLMO対策にもなるということです。品質管理とLLMO対策を別々のプロジェクトとして走らせるのではなく、統合して運用してください。
まとめ: 品質管理は「コスト」ではなく「投資」
生成AIコンテンツの品質管理を、最後に3つのポイントに集約します。
1. Googleは「AI記事を禁止」していない。禁止しているのは「低品質な記事」だ。 AI記事だから減点されるのではなく、E-E-A-Tを満たさない記事が減点される。品質管理を正しく設計すれば、AIは生産性を飛躍的に高めるツールになる。
2. Q-TEFフレームワークで品質を定量化せよ。 Quality・Trust・Experience・Freshnessの4軸で評価し、Bランク(30点)以上を公開基準にする。感覚的な「これで大丈夫かな」を排除し、チェックリストベースの品質管理に移行する。
3. AI活用度レベルに応じて品質管理の工数を配分せよ。 L1(素材収集)とL5(全自動)では必要な品質管理工程がまったく異なる。コンテンツタイプごとにレベルを設定し、リスクに応じた工数配分を行う。
品質管理は記事制作のスピードを落とすものではありません。品質管理があるからこそ、AIの生産性を安全に最大化できるのです。チェックリストを公開フローに組み込み、四半期レビューを仕組み化してください。それだけで、Googleアップデートへの耐性が格段に上がります。

この記事の著者
Agentic Base 編集部
AIエージェントとWebメディア運用の知見を活かし、実践的なナレッジを発信しています。



