「お客様の声を集めてはいるが、活かせていない」。 この悩みは、企業規模を問わず最も多く聞かれるCX(顧客体験)課題のひとつです。アンケートの自由記述は溜まる一方、サポートチケットのテキストは読み切れず、SNSの投稿は把握すらできていない。月次レポートにまとめる頃には鮮度が落ち、具体的な改善アクションにつながらないまま次の四半期を迎える -- このパターンに心当たりがある方は少なくないでしょう。
2026年、生成AIの実用化がこの構造を根本から変えつつあります。ChatGPTやClaudeに代表されるLLM(大規模言語モデル)は、従来のテキストマイニングツールでは不可能だった「文脈を踏まえた感情分類」「要因の自動推定」「改善案の生成」までを一気通貫で処理できるようになりました。辞書登録も、分類ルールのメンテナンスも不要です。
本稿では、AI×VOC分析を「始める」ための実践ガイドとして、独自のHEARフレームワーク(Harvest・Extract・Act・Review)を軸に、データ収集から改善実行までの全工程を解説します。プロンプト例、ツール比較、業種別事例まで、明日から使える内容に絞りました。
VOC分析とは何か -- 基本概念の整理
VOC(Voice of Customer)分析とは、顧客が発するあらゆる「声」を体系的に収集・分類・分析し、製品やサービスの改善に結びつけるプロセスです。ここでいう「声」は、アンケート回答やサポート問い合わせだけではありません。SNSの投稿、レビューサイトの評価、営業担当が聞いたヒアリングメモ、解約時のフィードバックなど、顧客が自社に対して発信するすべての情報がVOCに含まれます。
VOC分析の目的は、大きく3つに集約されます。
- 課題の早期発見: 不満や離脱の兆候を、数値指標に現れる前にテキストから検出する
- 改善の優先順位づけ: 多数の声を構造化し、「何を先に直すべきか」を定量的に判断する
- 顧客理解の深化: 定量データ(NPS、CSAT)だけでは見えない「なぜそう思ったか」の背景を把握する
従来のVOC分析は、Excelでの手動集計、あるいはテキストマイニングツール(形態素解析+頻出語抽出)で行われてきました。しかし、これらの手法にはいくつかの構造的な限界があります。
なぜ今、VOC分析にAIが必要なのか
従来手法の3つの限界
テキストマイニングツールは、分類精度を上げるために辞書やルールの継続的なメンテナンスが必要です。新しい製品名、業界用語、スラングが登場するたびに辞書を更新しなければ、分類漏れが発生します。ある金融機関では、辞書メンテナンスだけで月20時間のリソースを割いていました。
限界2: 文脈理解の不足従来のテキストマイニングは単語の出現頻度を軸に分析するため、文脈によって意味が変わる表現を正しく処理できません。「期待しています」は肯定的に見えますが、クレーム文脈では「改善を期待している=現状に不満」という意味になります。この種の誤分類が蓄積すると、分析結果への信頼性が損なわれます。
限界3: 分析から改善への断絶頻出語のワードクラウドや感情の正負比率が出ても、「では何をすべきか」が示されません。分析チームと改善チームが別部署である場合、分析結果が「報告書」として共有されるだけで、具体的なアクションに変換されないまま放置されるケースが後を絶ちません。
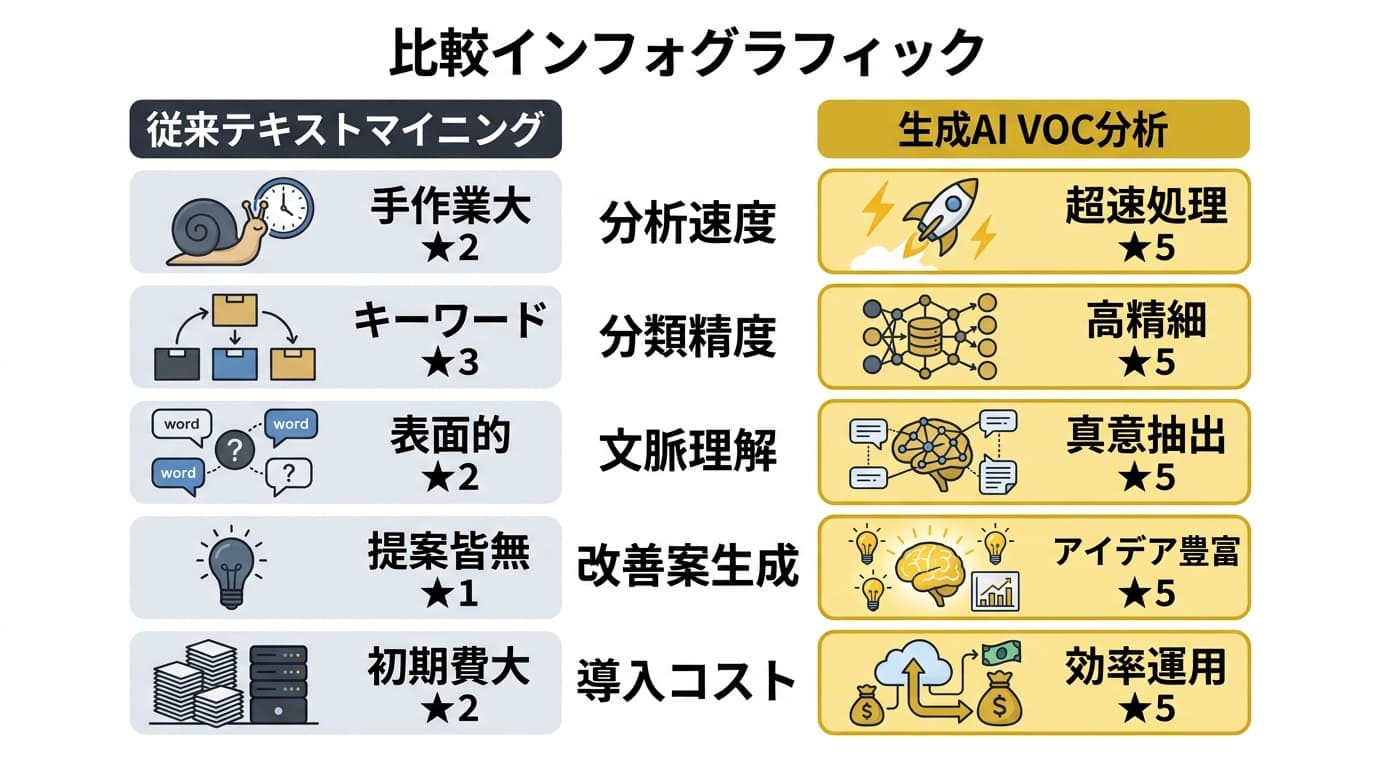
従来テキストマイニング vs 生成AI VOC分析
| 比較項目 | 従来テキストマイニング | 生成AI VOC分析 |
|---|---|---|
| 分類方法 | 辞書・ルールベース | LLMによる文脈理解 |
| 初期設定 | 辞書構築に2〜4週間 | プロンプト設計で1〜3日 |
| メンテナンス | 月次の辞書更新が必須 | プロンプト微調整のみ |
| 感情分析精度 | 正負判定で70〜80% | 多段階感情+文脈考慮で85〜93% |
| 多言語対応 | 言語ごとに辞書が必要 | LLMが多言語をネイティブ処理 |
| 要因分析 | 共起語から推定(手動解釈) | 要因を自然言語で自動推定 |
| 改善案生成 | 非対応(人力で作成) | 分析結果から改善案を自動提案 |
| コスト構造 | ツールライセンス月10〜50万円 | API従量課金 月1〜10万円 |
| 向いている場面 | 定型的な大量データの定点観測 | 多様なソースの探索的分析 |
生成AIの最大の強みは、「分類して終わり」ではなく「なぜその声が出ているのか」「どう改善すべきか」まで一気通貫で処理できる点にあります。これにより、VOC分析の価値が「レポート作成」から「改善アクションの起点」へとシフトします。
HEARフレームワーク -- AI×VOC分析の4ステップ
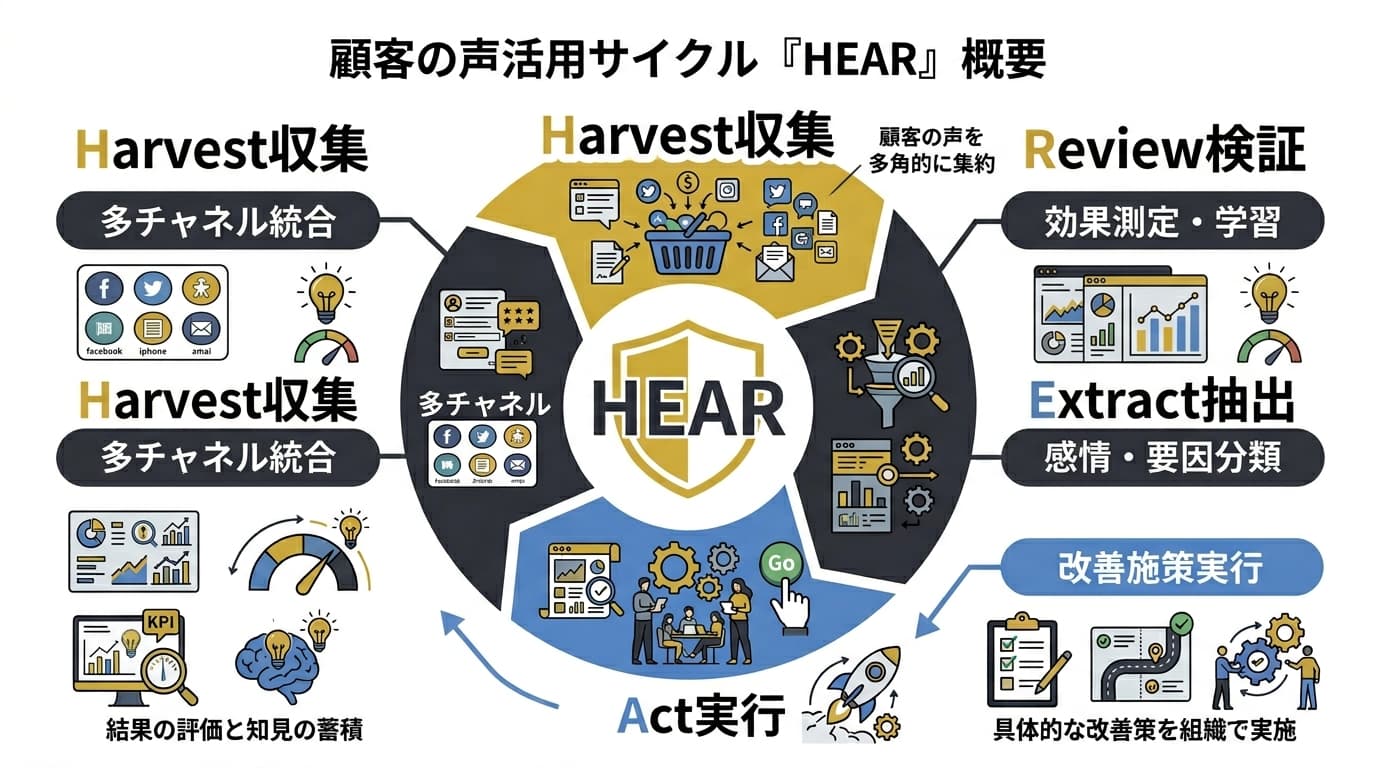
AI×VOC分析を組織的に運用するために、本稿ではHEARフレームワークを提案します。Harvest(収集)・Extract(抽出)・Act(実行)・Review(検証)の4ステップを継続的に回すことで、VOCデータが改善施策に確実につながる仕組みを構築します。
H -- Harvest(収集): 多チャネルからVOCを集約する
VOC分析の質は、収集するデータの網羅性と鮮度で決まります。特定チャネルだけを見ていると、声の偏りが発生し、実態を反映しない分析結果になります。
収集すべき主要チャネルと特性:| データソース | データ形式 | 鮮度 | 収集の自動化 | 分析価値 |
|---|---|---|---|---|
| サポートチケット | 構造化テキスト | リアルタイム | API連携で自動 | 非常に高い(具体的な不満) |
| アンケート自由記述 | 半構造化テキスト | 月次〜四半期 | フォーム連携で自動 | 高い(意図的なフィードバック) |
| SNS・レビュー | 非構造化テキスト | リアルタイム | クローリングで自動 | 高い(本音が出やすい) |
| 営業ヒアリングメモ | 非構造化テキスト | 都度 | CRM入力に依存 | 中〜高(商談文脈あり) |
| 解約時フィードバック | 構造化テキスト | 都度 | フォーム連携で自動 | 非常に高い(離脱理由の直接情報) |
| 通話録音の書き起こし | 非構造化テキスト | リアルタイム | 音声認識で自動 | 高い(感情が反映される) |
- Zapier/Make/n8nで自動パイプラインを構築する: Googleフォーム → スプレッドシート → AI分析の流れを自動化すれば、手動作業ゼロでVOCが蓄積されます
- CRMへの入力を「習慣化」する: 営業ヒアリングメモは最も失われやすいVOCです。Salesforce/HubSpotの商談メモ欄にテンプレートを設定し、入力を定型化してください
- 収集時点で個人情報をマスキングする: AI分析に渡す前に、氏名・メールアドレス・電話番号を自動マスキングする処理を挟みます。正規表現で80%はカバーでき、残りはLLMに「個人情報をXXXに置換してから返してください」と指示すれば対応可能です
E -- Extract(抽出): AIで感情・要因・カテゴリを分類する
収集したVOCデータを、AIを使って構造化します。ここが従来手法と最も差がつく工程です。
AIで行う3つの抽出処理: 1. 感情分類(センチメント分析)単純な正負判定ではなく、5段階以上の感情軸で分類します。「怒り」「不満」「中立」「満足」「感動」のように粒度を上げることで、対応の優先度判断に使えるようになります。
2. 要因分類(カテゴリ分類)「この声は何に関する不満/評価か」を自動分類します。製品品質、価格、UI/UX、サポート対応、配送、競合比較など、自社のビジネスに合ったカテゴリ体系を定義し、AIに分類させます。
3. 要因推定(Root Cause Analysis)感情とカテゴリだけでなく、「なぜその感情が生じたか」の背景要因まで推定します。これは生成AI特有の能力で、従来のテキストマイニングでは実現できなかった分析です。
A -- Act(実行): 優先度をつけて改善施策を実行する
分析結果を改善アクションに変換するステップです。ここが最も「やりっぱなし」になりやすい工程でもあります。
優先度の決め方: Impact × Frequencyマトリクス| 発生頻度: 高 | 発生頻度: 低 | |
|---|---|---|
| 影響度: 高 | 最優先で対応(解約直結の不満など) | 次スプリントで対応 |
| 影響度: 低 | バックログに積む | 経過観察 |
AIが分類した感情スコアとカテゴリの出現頻度を掛け合わせることで、このマトリクスを自動生成できます。毎月「今月の改善候補トップ5」をAIに出力させ、関連部署のミーティングで共有するだけで、VOC分析と改善実行の断絶を防げます。
改善施策の割り当て:- プロダクトチーム: UI/UXや機能に関するVOC → 開発バックログに反映
- CSチーム: サポート対応に関するVOC → FAQ更新・対応プロセスの改善
- マーケティングチーム: 期待値ギャップに関するVOC → メッセージングの修正
- 経営層: 解約理由・競合比較に関するVOC → 戦略判断のインプット
R -- Review(検証): 施策効果を計測し次サイクルへ
改善施策を実行したら、その効果をVOCデータの変化で検証します。「施策を打つ前の1か月間」と「施策を打った後の1か月間」で、該当カテゴリのネガティブ比率がどう変化したかを比較します。
検証指標の例:- ネガティブVOC比率の変化(カテゴリ別)
- 同一テーマの再発率
- NPS/CSATスコアの変動
- 解約率の変化(該当セグメント)
このR(Review)の結果が、次のH(Harvest)の収集設計にフィードバックされます。改善が進んだカテゴリの監視頻度を下げ、新たに浮上した課題の収集を強化する。このサイクルを月次で回すことで、VOC分析が「やりっぱなし」にならない運用体制が構築されます。
VOCデータソース×分析手法のマトリクス
データソースによって最適なAI分析手法は異なります。以下のマトリクスを参考に、自社の状況に合った組み合わせを選んでください。
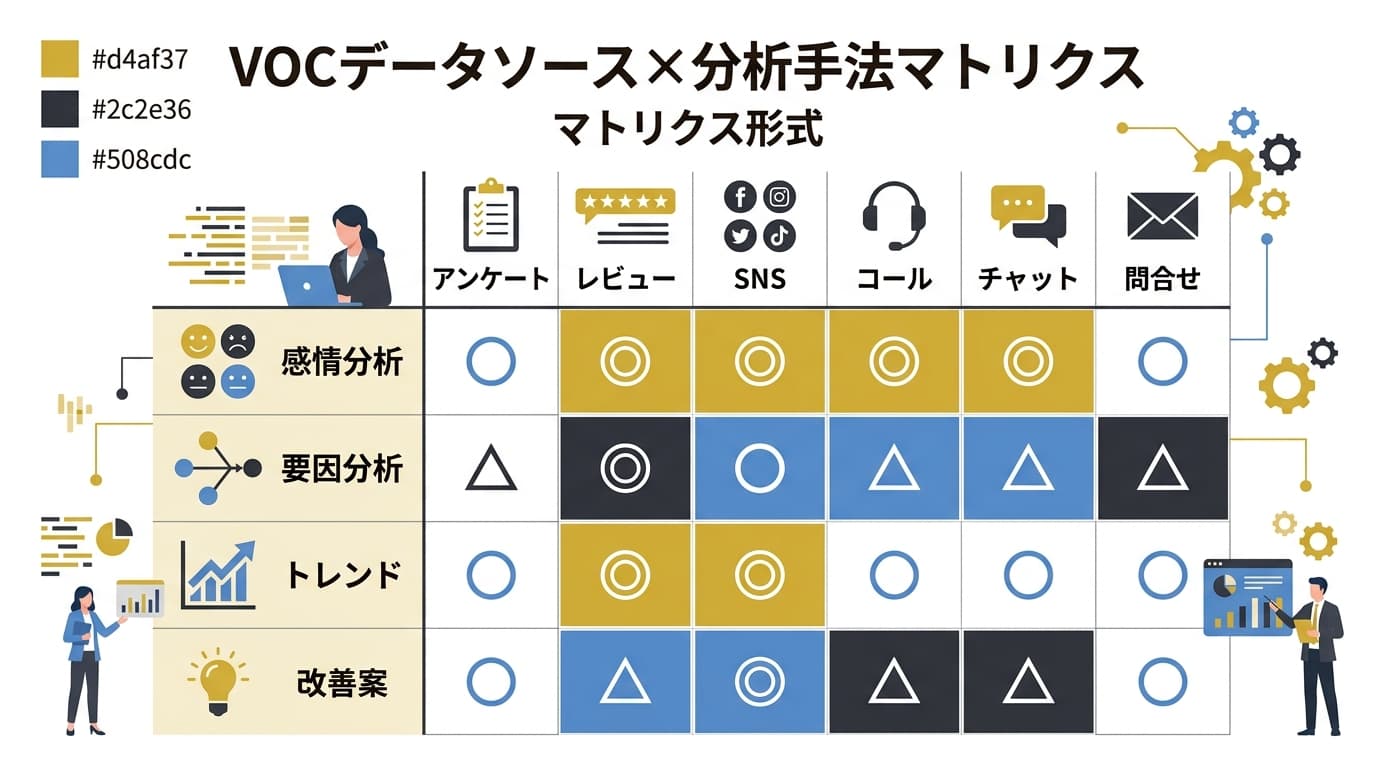
| データソース | 感情分類 | カテゴリ分類 | 要因推定 | トレンド検出 | 改善案生成 | 推奨手法 |
|---|---|---|---|---|---|---|
| サポートチケット | 必須 | 必須 | 推奨 | 推奨 | 推奨 | LLM API + 自動パイプライン |
| アンケート自由記述 | 必須 | 必須 | 必須 | 任意 | 推奨 | LLMバッチ処理 |
| SNS/レビュー | 必須 | 推奨 | 任意 | 必須 | 任意 | ソーシャルリスニング + LLM |
| 営業ヒアリング | 任意 | 必須 | 必須 | 任意 | 推奨 | CRM連携 + LLM要約 |
| 解約理由 | 必須 | 必須 | 必須 | 必須 | 必須 | LLM深掘り分析 |
| 通話書き起こし | 推奨 | 推奨 | 推奨 | 任意 | 任意 | 音声AI + LLM二段階処理 |
AI×VOC分析の実践 -- プロンプト例と活用法
ここからは、ChatGPTやClaudeを使ったVOC分析の具体的なプロンプト例を紹介します。API経由でもWebチャットでも利用可能ですが、大量データを処理する場合はAPI経由を推奨します。
実践1: 感情分類プロンプト
あなたはVOC分析の専門家です。以下の顧客フィードバックを分析してください。
## 分析対象
{ここにVOCテキストを貼り付け}
## 分析指示
各フィードバックについて、以下の形式でJSON出力してください:
{
"id": "連番",
"original_text": "元のテキスト(50文字以内に要約)",
"sentiment": "怒り|不満|中立|満足|感動 の5段階",
"sentiment_score": "-2〜+2の数値",
"confidence": "0.0〜1.0の確信度"
}
## 判定ルール
- 丁寧な言葉遣いでも文脈上の不満が含まれる場合は「不満」と判定
- 「期待しています」「今後の改善を望みます」は不満の婉曲表現として扱う
- 事実のみの記述で感情が読み取れない場合は「中立」
- 複数の感情が混在する場合は、最も強い感情で判定このプロンプトのポイントは、判定ルールを明示的に定義している点です。「丁寧だが不満を含む表現」の扱いを事前に指示しておくことで、従来のテキストマイニングでは誤分類されがちだったケースをカバーできます。
実践2: 要因分析プロンプト
あなたはVOC分析の専門家です。以下の顧客フィードバック群から、
不満・要望の根本原因を分析してください。
## 分析対象
{ここに複数のVOCテキストを貼り付け}
## 分析指示
1. フィードバックを以下のカテゴリに分類してください:
- 製品品質(機能・バグ・性能)
- UI/UX(操作性・デザイン・導線)
- 価格・プラン(料金体系・コスパ)
- サポート対応(対応速度・品質・チャネル)
- オンボーディング(初期設定・学習コスト)
- ドキュメント(ヘルプ・マニュアル・FAQ)
- 競合比較(他社製品との比較言及)
2. 各カテゴリについて以下を出力:
- 該当件数と全体に占める割合
- 代表的な声(原文引用)3件
- 根本原因の推定(なぜこの不満が生じているか)
- 改善インパクトの予測(高/中/低)
3. カテゴリ横断で見えるパターンがあれば指摘してください実践3: 改善案生成プロンプト
あなたはプロダクトマネージャーです。VOC分析の結果から改善施策を提案してください。
## VOC分析結果サマリ
{ここに要因分析の出力結果を貼り付け}
## 提案条件
- 開発リソース:エンジニア3名、デザイナー1名
- 対応可能期間:次の四半期(3か月)
- 重視する指標:解約率の低減、NPS改善
## 出力フォーマット
各施策について以下を記載:
| 施策名 | 対応するVOC | 期待効果 | 工数目安 | 優先度 |
|---|---|---|---|---|
| ... | ... | ... | ... | S/A/B/C |
- S: 今スプリントで着手(解約直結)
- A: 今四半期で完了(NPS影響大)
- B: 次四半期以降(中期的改善)
- C: バックログ(将来検討)
施策は最大10件、優先度S・Aを中心に提案してください。実践4: 時系列トレンド分析プロンプト
あなたはデータアナリストです。以下は直近3か月のVOCデータを月別に集計した
ものです。トレンドの変化を分析してください。
## データ
{月別のカテゴリ別件数・感情スコアの推移を貼り付け}
## 分析指示
1. 前月比で件数が20%以上増加したカテゴリを特定
2. 感情スコアが悪化傾向にあるカテゴリを特定
3. 新たに出現したキーワード・テーマがあれば報告
4. 改善施策を実施済みのカテゴリについて、効果が出ているか判定
5. 来月に注視すべきリスク要因を3つ挙げるAI VOC分析のツール比較【2026年版】
VOC分析に使えるツールは大きく3カテゴリに分かれます。自社の規模・予算・既存ツールとの相性で選んでください。
カテゴリ1: 汎用LLM API(ChatGPT / Claude)
| 項目 | 詳細 |
|---|---|
| 代表サービス | OpenAI API (GPT-4o)、Anthropic API (Claude 3.5/4) |
| 月額コスト目安 | 月1,000件処理で5,000〜30,000円 |
| 強み | 柔軟なプロンプト設計、多言語対応、改善案生成まで対応 |
| 弱み | パイプライン構築は自前、ダッシュボード機能なし |
| 向いている企業 | 開発リソースがある、既存BIツールと組み合わせたい企業 |
APIを使う場合の典型的なアーキテクチャは以下の通りです。
- データソース(Googleフォーム、Zendesk、SNS API等)からn8n/Zapierで自動取得
- 前処理(個人情報マスキング、重複排除)
- LLM APIに送信(感情分類→要因分析→改善案生成の3段階)
- 結果をスプレッドシートまたはBIツール(Looker Studio、Tableau)に出力
- 月次レポートを自動生成してSlack通知
カテゴリ2: VOC特化AIツール
| ツール名 | 主な機能 | 月額目安 | 特徴 |
|---|---|---|---|
| BECAUSE | 感情分析、要因分類、ダッシュボード | 15万円〜 | 日本語特化、導入支援あり |
| Medallia | オムニチャネルVOC統合、予測分析 | 50万円〜 | エンタープライズ向け、グローバル対応 |
| Qualtrics XM | サーベイ+AI分析統合 | 30万円〜 | アンケート設計からAI分析まで一気通貫 |
| 見える化エンジン | テキストマイニング+AI分析 | 20万円〜 | 日本語の形態素解析に強い |
| Re:lation | カスタマーサポート+VOC分析 | 5万円〜 | 問い合わせ管理と分析が統合 |
カテゴリ3: CRM/CS統合型
| ツール名 | VOC分析機能 | 月額目安 | 特徴 |
|---|---|---|---|
| Salesforce Einstein | Service Cloud内の会話分析、感情検出 | 既存契約に追加 | CRMデータとの自動連携 |
| Zendesk AI | チケット分類、感情分析、自動回答 | 既存契約に追加 | サポート業務との統合が自然 |
| HubSpot AI | フィードバック分析、NPS自動集計 | 既存契約に追加 | マーケ〜CSまでワンストップ |
- 月間VOC件数が500件未満 + 開発リソースあり: 汎用LLM API
- 月間VOC件数が500件未満 + 開発リソースなし: Re:lation等の軽量ツール
- 月間VOC件数が500〜5,000件: VOC特化AIツール
- 月間VOC件数が5,000件超 + 既存CRMあり: CRM統合型
- グローバル展開 + 多言語対応が必要: Medallia / Qualtrics
VOC分析の成熟度モデル
自社のVOC分析がどの段階にあるかを把握し、次のレベルに進むための施策を明確にすることが重要です。
Lv1: 手動集計フェーズ Excelやスプレッドシートで月次集計。担当者が目視で分類し、報告書を作成。分析に1〜2週間かかり、改善施策に結びつくことは稀です。多くの企業がこの段階に留まっています。
Lv2: テキストマイニングフェーズ 専用ツールを導入し、頻出語の抽出や共起語分析を自動化。ワードクラウドやネガポジ比率は出るが、「だから何をすべきか」の部分は人間が判断。辞書メンテナンスのコストが課題になります。
Lv3: 生成AI補助フェーズ LLMを活用して感情分類・要因推定・改善案生成を自動化。分析速度が劇的に向上し、月次だったレポートが週次または日次に。ただし、AIの出力を人間がレビューする運用が必要です。
Lv4: AI自律運用フェーズ VOCの収集から分析、改善施策の起案、効果測定までの一連のプロセスがAIエージェントで自動化。人間は戦略的な判断と例外対応に集中。2026年時点では先進的な企業がこのレベルに到達しつつあります。
業種別VOC活用事例
事例1: EC(アパレルD2C) -- 返品理由の構造化で返品率15%削減
課題: 月間3,000件の返品のうち、返品理由の自由記述が「サイズが合わない」「イメージと違う」に集中しており、具体的な改善アクションに結びつかなかった。
AI VOC分析の適用:返品理由の自由記述をClaudeのAPIで分析し、「サイズが合わない」を以下の5つのサブカテゴリに自動分類しました。
| サブカテゴリ | 割合 | 根本原因(AI推定) | 改善施策 |
|---|---|---|---|
| 丈が長い/短い | 35% | サイズ表記がS/M/Lのみで数値なし | 商品ページに実寸表記を追加 |
| 肩幅/身幅が合わない | 25% | 体型バリエーションの考慮不足 | 着用モデルの体型情報を表示 |
| 素材の伸縮性が想定外 | 20% | 素材説明が「コットン100%」のみ | 伸縮性/厚み/透け感を5段階表示 |
| 写真と色味が違う | 15% | 撮影環境の色温度ばらつき | 撮影ガイドライン統一+環境光補正 |
| その他 | 5% | - | 個別対応 |
結果: サブカテゴリ別の改善施策を3か月で実行した結果、返品率が22%→18.7%に低減。年間の返品処理コストを約1,200万円削減しました。
事例2: SaaS(プロジェクト管理ツール) -- 解約理由分析でチャーン率を改善
課題: 月次解約率が2.1%で業界平均(1.5%)を上回っていた。解約時アンケートの回収率は40%で、自由記述の分析が追いついていなかった。
AI VOC分析の適用:解約時フィードバック、過去6か月のサポートチケット、利用ログを統合し、ChatGPT APIで要因分析を実施。解約理由を以下のように構造化しました。
- 機能不足(38%): 特にガントチャート機能の要望が集中。「XXツールに乗り換えた」という競合言及が多数
- オンボーディング失敗(27%): 導入後30日以内にコア機能を使い始めていないユーザーの解約率が5倍
- 価格(20%): 小規模チーム(5名以下)で「1人あたりの単価が高い」という声が集中
- パフォーマンス(15%): レスポンス遅延に関する不満が直近3か月で急増
結果: ガントチャート機能の優先開発、オンボーディングフローの再設計(チュートリアル動画の追加)、小規模チーム向けプランの新設により、6か月で月次解約率が2.1%→1.4%に改善しました。
事例3: 飲食チェーン -- Googleレビュー分析で店舗別QSC改善
課題: 全国120店舗のGoogleレビュー(月間約2,000件)を本部で一括管理していたが、分析が追いつかず、低評価レビューへの対応が遅れていた。
AI VOC分析の適用:Google Maps APIでレビューを自動取得し、店舗別・カテゴリ別(Q:品質、S:サービス、C:清潔さ)に自動分類。週次で各店舗のQSCスコアをダッシュボードに表示し、スコアが急落した店舗にアラートを配信する仕組みを構築しました。
AIが検出した特徴的なパターンとして、「料理は美味しいがスタッフの対応が冷たい」という声が特定の時間帯(ランチタイム)に集中していることが判明。これはアルバイトスタッフの教育不足が原因であることが特定でき、時間帯別の接客マニュアル整備につながりました。
結果: Googleレビューの平均星数が3.6→3.9に改善(6か月間)。レビュー返信率も15%→85%に向上しました。
事例4: 金融(ネット証券) -- コールセンター音声のVOC分析
課題: コールセンターの通話録音は月間15,000件に達するが、品質管理チームが抽出聴取できるのは全体の3%程度。顧客の不満がサイレントに蓄積していた。
AI VOC分析の適用:音声認識AI(Whisper API)で通話を書き起こし、LLMで以下の分析を自動実行しました。
- 感情変化の検出: 通話開始時と終了時の感情スコアを比較し、「対応後に悪化した通話」を自動抽出
- 要因分類: 問い合わせ内容を「口座操作」「商品説明」「手数料」「システムトラブル」「苦情」に自動分類
- オペレーター評価: 応対品質のスコアリング(傾聴度、解決率、エスカレーション適切性)を自動算出
結果: 品質管理チームのモニタリング対象を全通話の3%→100%に拡大しつつ、工数は据え置き。顧客満足度(通話後アンケート)が68点→78点に改善しました。
AI×VOC分析の導入ステップ -- 90日プラン
Phase 1: 準備(1〜2週目)
やること:- 現状のVOCデータソースを棚卸しする(何が、どこに、どのくらいあるか)
- 分析の目的を明確にする(解約防止、CS改善、プロダクト改善のどれが最優先か)
- PoC(概念実証)で使うデータセットを100〜200件抽出する
- 個人情報のマスキングルールを決める
- VOCデータソースの一覧表を作成した
- 分析の主目的を1つに絞った
- PoCデータセットを準備した
- 個人情報マスキングの方法を確認した
Phase 2: PoC実施(3〜4週目)
やること:- 汎用LLM(ChatGPT or Claude)のWebチャットでまず試す
- 前述のプロンプト例を使い、PoCデータセットを分析する
- 分類精度を人間の目で検証する(100件中何件が正しく分類されたか)
- プロンプトを調整して精度を80%以上に引き上げる
- 感情分類の精度: 80%以上
- カテゴリ分類の精度: 75%以上
- 要因推定の妥当性: 担当者が「そうだと思う」と納得する割合70%以上
- 改善案の実用性: 提案された施策の50%以上が「検討に値する」と判断される
Phase 3: パイプライン構築(5〜8週目)
やること:- API経由での自動処理パイプラインを構築する
- データソースからの自動取得を設定する(Zapier/n8n/Make)
- 結果の出力先を整備する(スプレッドシート or BIダッシュボード)
- 月次/週次の自動レポート生成を設定する
- トリガー: Googleフォーム新規回答 / Zendesk新規チケット / SNS API定期取得
- 前処理: 個人情報マスキング(正規表現ノード)
- AI分析: OpenAI/Anthropic APIノード(3段階プロンプト)
- 後処理: JSON解析 → スプレッドシート書き込み
- 通知: Slack通知(ネガティブスコアが閾値を超えた場合のみ)
Phase 4: 運用定着(9〜12週目)
やること:- 月次のVOCレビュー会議を設定する(関連部署の責任者が参加)
- 改善施策の実行と効果検証のサイクルを回し始める
- プロンプトの精度を継続的に改善する(誤分類パターンの分析)
- ROI(投資対効果)を計測する
| 項目 | 計算方法 |
|---|---|
| コスト削減 | VOC分析にかかっていた人件費 - AI運用コスト |
| 解約防止効果 | 解約率改善 × 顧客単価 × 顧客数 |
| 改善速度 | 課題発見から施策実行までのリードタイム短縮 |
| 網羅性向上 | 分析対象VOC件数の増加率 |
よくある失敗パターンと回避策
失敗1: 「分析して満足」症候群
症状: AIを使って精度の高い分析レポートが出るようになったが、改善アクションにつながっていない。分析チームと改善チーム(開発、CS、マーケ)が分離しているため、レポートが「読まれない資料」になっている。
回避策: HEARフレームワークのA(Act)を制度化する。月次のVOCレビュー会議に改善担当者を必ず出席させ、「今月のアクションアイテム3つ」を会議内で決定し、翌月のR(Review)で進捗を確認する仕組みにします。
失敗2: 過信によるAI出力の無検証運用
症状: AIの分類結果をそのまま信頼し、人間によるレビューを省略。誤分類が蓄積し、改善の方向性を誤る。特に「業界固有の専門用語」や「自社製品特有の表現」でAIが的外れな分類をするケースが見落とされる。
回避策: 導入後3か月間は、AIの出力を週次でサンプリング検証(50件程度)する。誤分類パターンが見つかったら、プロンプトに「判定ルール」として追記する。精度が安定したら検証頻度を月次に移行します。
失敗3: データソースの偏り
症状: サポートチケットだけを分析対象にしているため、「問い合わせをしない不満顧客」の声が拾えない。結果として、サイレント解約(不満を言わずに離脱する顧客)を防止できない。
回避策: HEARフレームワークのH(Harvest)で複数チャネルを網羅する。特にSNS/レビューと解約時フィードバックは、サポートチケットでは拾えない「本音」が含まれている可能性が高いため、優先的に収集対象に加えてください。
まとめ -- AI×VOC分析で「聞く力」を組織の武器にする
VOC分析の本質は、顧客の声を「聞く」ことではなく、「聞いた結果を改善に変換する」ことにあります。生成AIは、この変換プロセスを劇的に加速します。
本稿のポイントを整理します。- HEARフレームワークで収集→抽出→実行→検証のサイクルを回す
- 従来のテキストマイニングから生成AI分析への移行で、辞書メンテナンス不要・文脈理解・改善案生成が実現する
- プロンプト設計が分析精度を左右する。感情分類、要因分析、改善案生成の3段階で使い分ける
- ツール選定は月間VOC件数と開発リソースで判断する。500件未満なら汎用LLM API、それ以上はVOC特化ツールまたはCRM統合型
- 90日間の導入プランで、PoCからパイプライン構築、運用定着まで段階的に進める
- 最大の失敗は「分析して満足」。Act(実行)とReview(検証)を制度化することで、VOCが組織の改善エンジンになる
まずは手元にあるVOCデータ100件をChatGPTやClaudeに投入し、感情分類プロンプトを試してみてください。30分で「従来手法との違い」を体感できるはずです。そこから先は、HEARフレームワークに沿って収集チャネルを広げ、パイプラインを構築し、改善サイクルを回していく。顧客の声を組織の「聞く力」に変えるAI×VOC分析の第一歩は、意外なほどシンプルに始められます。

この記事の著者
Agentic Base 編集部
AIエージェントとWebメディア運用の知見を活かし、実践的なナレッジを発信しています。