「社内のナレッジをAIに活用したいけれど、エンジニアに頼む余裕がない」。こうした相談が急増しています。2024年のオープンソース公開から爆発的に成長したDifyは、GitHub Stars 58,000超、クラウド版で13万以上のアプリが稼働するノーコードAIプラットフォームです。しかし、「Difyの使い方」を解説する記事は山ほどあっても、業務で本当に使えるエージェントをどう設計するかを体系的に示す記事はほとんどありません。
私たちはクライアント企業のAIエージェント導入支援で、Dify・n8n・Zapierを業務特性に応じて使い分けてきました。その中で見えてきたのは、ツールの機能差よりも「設計判断の精度」が成否を分けるという事実です。本記事では、UIの操作手順ではなく「業務課題から逆算してDifyのどの機能をどう組み合わせるか」という設計パターンを、実務での導入経験をもとに解説します。
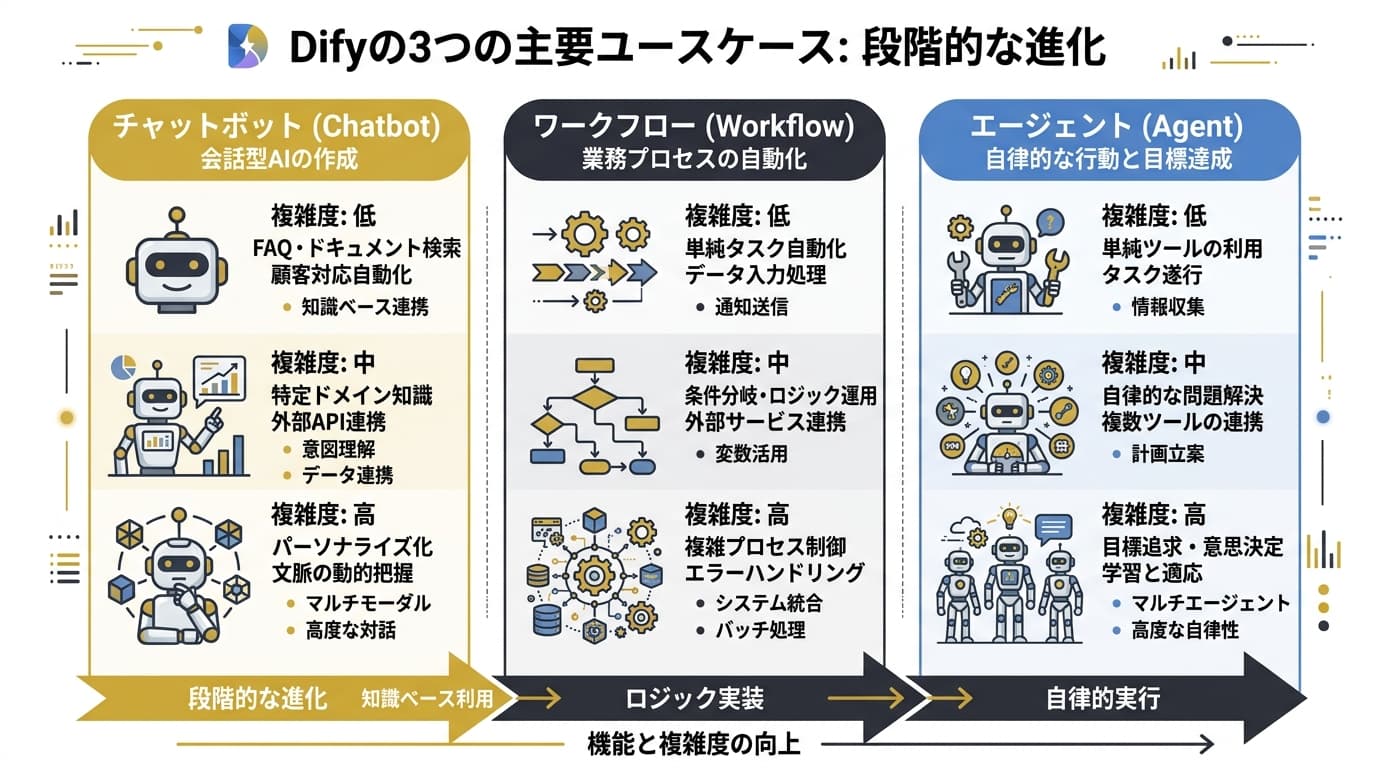
図1: Difyによるノーコードエージェント設計の全体像
なぜ今 Dify なのか — ノーコードAIエージェント市場の変化
ノーコードAIの選択肢が増える中で、Difyが急速にシェアを伸ばしている背景には3つの構造的理由があります。
第一に、完全なオープンソース(Apache 2.0)でありながら機能制限がないこと。 Community Editionでもワークフロー、エージェント、RAG、ナレッジベース管理のすべてが使えます。多くの競合がコア機能を有料プランに限定する中、これは大きな差別化要因です。
第二に、RAGが組み込みで提供されていること。 n8nやMakeのようなワークフロー自動化ツールでRAGを構築するには、ベクトルDBの別途セットアップやチャンク処理の実装が必要です。Difyでは、PDFをアップロードしてナレッジベースを作成するだけで、ベクトル検索が即座に動きます。
第三に、日本企業での本格採用が始まっていること。 価格比較サイトを運営するカカクコムは、Dify Enterpriseを全社導入し、導入1ヶ月で社員の30%がアカウント登録・70以上のアプリを構築し、最終的に社員の75%が登録、約950個のAIアプリが稼働するに至っています1。商品データ抽出ツールはわずか3時間で本番稼働しました。NTTデータとJIP(日本情報処理サービス)もDify Enterpriseを技術基盤とした戦略提携を発表しています2。
ただし、Difyが「使える」ことと、Difyで「使えるエージェントを作れる」ことは別の話です。カカクコムが3時間で本番稼働できた理由は、UIの使いやすさだけではなく、「この業務にはこのアプリケーションタイプ」という設計判断が正しかったからです。AI導入で失敗する7つの課題で解説しているように、ツール選定の前に業務課題の構造化ができていないと、どんなに優れたプラットフォームでもPoC止まりになります。
4つのアプリケーションタイプと設計判断ツリー
Difyは4種類のアプリケーションタイプを提供しています。最初に必要なのは、自分の業務課題にどのタイプが最適かを判断することです。
- チャットボット: 会話インターフェースで質問に回答する。ナレッジベースと組み合わせてFAQボットを構築
- テキストジェネレーター: 入力テンプレートに基づいてテキストを一括生成する。レポートや翻訳に活用
- ワークフロー: 複数のステップを条件分岐やループで繋ぎ、確定的な処理を自動実行する
- エージェント: LLMが自律的にツール選択と推論を繰り返し、複雑な課題を解決する
この4タイプの選択を誤ると、ワークフローで十分な業務にエージェントを使って不安定になったり、エージェントが必要な業務をチャットボットで無理やり実装して精度が出なかったりします。
判断の分岐点は2つです。
分岐1: 手順は確定しているか。 毎回同じ手順で処理が完結する業務(申請処理、定型レポート生成、データ変換)は、ワークフローが最適です。条件分岐やループで例外処理も組み込めます。LLMの推論に頼らない分、結果が安定し、コストも低く抑えられます。
分岐2: 自律的な判断が必要か。 手順が確定していない業務のうち、単純な質問応答で完結するものはチャットボットを選びます。一方、「複数の情報源を調べて比較し、最適な回答を組み立てる」「状況に応じてツールを選択して実行する」ような業務はエージェントが必要です。
テキストジェネレーターの位置づけ
テキストジェネレーターは、ワークフローの簡易版と考えてください。単一ステップのテンプレート生成に特化しており、メール文面の生成や文書の要約など、入力→出力が1対1で完結する処理に向いています。複数ステップが必要になったらワークフローに移行します。
設計パターン別レシピ — この業務にはこのパターン
ここからは、3つの代表的な業務シナリオに対する設計パターンを具体的に示します。
レシピ1: 社内FAQボット(チャットボット + RAG)
業務シナリオ: 社内規程、マニュアル、FAQ文書をAIが参照し、従業員の質問に自然言語で回答する。
設計のポイント:
このシナリオではチャットボット + ナレッジベースの組み合わせが最適です。エージェントを使う必要はありません。理由は、回答に必要な情報が社内文書に閉じており、外部ツールの呼び出しや複雑な推論チェーンが不要だからです。RAGの仕組みと2026年の全体像で解説しているAgentic RAGまでは必要なく、シンプルなRetrieve-and-Generateパターンで十分対応できます。
具体例: 50名規模の製造業での導入ケース。 ある製造業のクライアントでは、品質管理マニュアル(PDF 120ページ)と作業手順書(Excel 35シート)をDifyのナレッジベースに取り込み、現場作業者向けのFAQボットを構築しました。従来は品質管理部門に電話で問い合わせていたため、1件あたり平均15分の対応時間がかかっていましたが、チャットボット導入後は即時回答が可能になり、品質管理部門の問い合わせ対応時間が月40時間から8時間に削減されました。ポイントは、PDFを事前にMarkdownに変換し、見出しベースのチャンク分割を適用したことです。PDF直接取り込みでは回答精度が62%でしたが、Markdown変換後は89%まで改善しました。
ナレッジベースの設計で最も重要なのは「1テーマ1ナレッジベース」の原則です。就業規則、経費精算マニュアル、IT手順書を1つのナレッジベースにまとめると、検索精度が大幅に低下します。テーマごとに分離し、チャットボット側で複数のナレッジベースを参照先として指定する方が精度が安定します。
チャンク戦略は3つの選択肢があります。
- 固定長分割(500〜1,000トークン): 最もシンプル。文書構造が統一されていない場合のデフォルト選択
- セマンティック分割: 意味の切れ目で自動分割。精度は高いが処理コストも高い
- 見出しベース分割: Markdownの見出し階層で分割。マニュアルや規程文書に最適
Difyのデフォルト設定ではドキュメント形式の複雑さ(テーブル、チャート含む)で精度72%という報告がありますが、適切なチャンク戦略とハイブリッド検索(ベクトル検索 + キーワードマッチング)の組み合わせで94%まで改善可能とされています3。
レシピ2: ドキュメント分析エージェント(エージェント + ツール)
業務シナリオ: 競合企業の公開レポートを読み込み、要点の抽出・比較分析・サマリー生成を自律的に行う。
設計のポイント:
このシナリオではエージェントが必要です。「どの情報を重要と判断するか」「比較の切り口をどう設定するか」という判断をLLMに委ねるためです。
Difyのエージェントは2つの推論戦略を提供しています。
- Function Calling: LLMがツールの呼び出しパラメータを直接生成する。GPT-4やClaude 3.5のようにFunction Callingをネイティブサポートするモデルで高速・安定
- ReAct(Reasoning + Acting): 「思考→行動→観察」のループを明示的に回す。推論過程が透明で、デバッグしやすい。ただしトークン消費が多い
使い分けの基準は「透明性の要求度」です。 分析結果の根拠を説明する必要がある業務(経営層への報告、コンプライアンス関連)ではReActを選びます。推論過程がログに残るため、「なぜこの結論に至ったか」を追跡できます。速度とコストを優先する定型的な処理ではFunction Callingを選びます。
ツール連携では、Web検索(Google/Bing)とコード実行(Pythonサンドボックス)の2つが基本セットです。Dify v1.0.0以降のプラグインシステムにより、120以上のプラグインから追加ツールを導入できます。
具体例: SaaS企業での競合分析エージェント。 あるBtoB SaaS企業では、四半期ごとに競合5社の料金改定・機能追加・プレスリリースを調査するレポートを作成していました。この作業に営業企画チームが毎回延べ20時間を費やしていたため、DifyのエージェントにWeb検索ツールとPythonサンドボックスを組み合わせた競合分析エージェントを構築しました。ReAct戦略を採用し、「情報収集→比較表作成→サマリー生成」の推論ループを自律実行させています。完全自動化ではなく、収集した情報の正確性を人間が確認するステップを挟むことで、レポート作成時間を20時間から4時間に短縮しつつ、経営層への報告品質も維持しています。
レシピ3: 定型業務ワークフロー(ワークフロー + 条件分岐 + HITL)
業務シナリオ: 見積書のドラフト生成→上長の承認→顧客への送付という一連の処理を自動化する。
設計のポイント:
手順が確定している業務はワークフローが最適です。このシナリオで重要なのは、どのステップに人間の承認を入れるかという設計判断です。
Dify v1.13.0で追加されたHuman-in-the-Loop(HITL)ノードにより、ワークフローの途中で人間の承認を待機するステップを挿入できるようになりました。HITL配置の判断基準は3つです。
- 金額閾値: 見積金額が一定額を超える場合のみ承認ステップを挿入(条件分岐 + HITL)
- リスク分類: 顧客セグメントや商品カテゴリに応じてリスクレベルを判定し、高リスクのみ人間が確認
- 全件承認: 導入初期は全件を人間が確認し、精度が安定してから段階的に自動化範囲を拡大
導入初期は全件承認からスタートし、1〜2ヶ月の運用データをもとに自動化範囲を広げるのが安全なアプローチです。最初から完全自動化を目指すと、例外ケースでの事故リスクが高まります。HITLの配置設計について体系的に学びたい場合は、Human-in-the-Loop設計の判断ツリーを参照してください。
具体例: 人材紹介会社での見積書自動生成。 ある人材紹介会社では、クライアント企業ごとに異なる手数料率・支払条件の見積書を月200件以上作成していました。Difyのワークフローで「CRMからクライアント情報を取得→手数料率テンプレートを適用→見積書ドラフトを生成→金額50万円以上は部長承認」というフローを構築。条件分岐ノードで金額閾値を判定し、HITLノードで承認待機する設計です。見積書作成の平均所要時間が45分から8分に短縮され、手数料率の適用ミスもゼロになりました。
RAGナレッジベース設計の実務ガイド
RAGはDifyの中核機能であり、エージェントの実用性を左右する最重要要素です。ここでは、検索精度を高めるための設計指針を整理します。
ドキュメント形式別の取り込み戦略
Difyは PDF、Excel、テキスト、Markdown、HTML など多様な形式に対応していますが、形式によって精度に差があります。
PDFは事前にMarkdownに変換するのが精度向上の定石です。PDFのレイアウト解析は不安定な場合があり、特にテーブルや2カラムレイアウトで情報が欠落するリスクがあります。Markdownに変換することで、見出し構造が明確になり、見出しベースのチャンク分割が正確に機能します。
Excelは1シート1ファイルに分割してからアップロードします。複数シートを含むExcelファイルは、シート間の関連性をDifyが認識できないため、検索精度が低下します。
ナレッジベース設計の3原則
原則1: 1テーマ1ナレッジベース。 前述のとおり、テーマの混在は検索ノイズの最大原因です。
原則2: チャンクオーバーラップを20%確保。 チャンク間の文脈の断絶を防ぐため、隣接チャンクと20%程度の重複を持たせます。Difyのチャンク設定画面でオーバーラップ量を指定できます。
原則3: メタデータを活用したフィルタリング。 ドキュメントのアップロード時に部門名、文書種別、更新日などのメタデータを付与し、検索時のフィルタリングに使います。ナレッジベースの規模が大きくなるほど効果が顕著です。
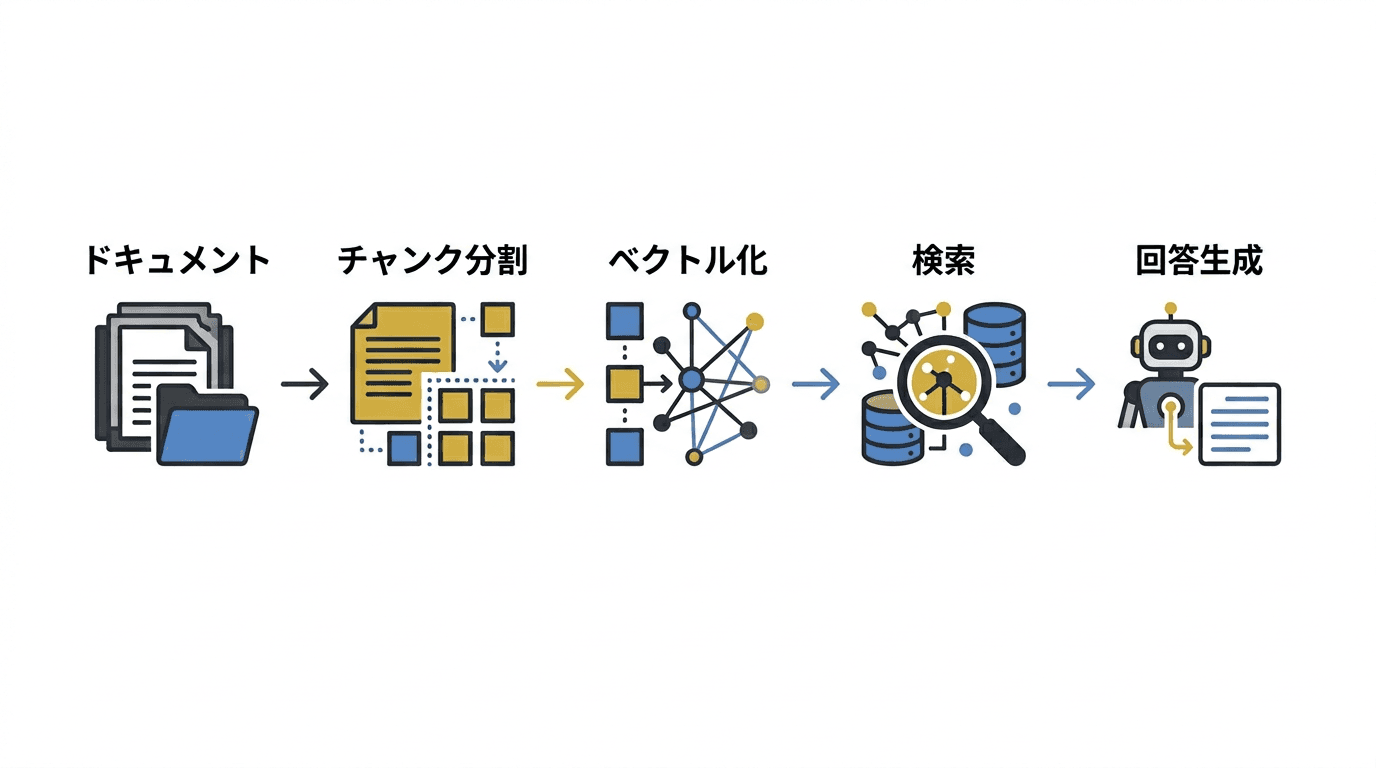
図3: RAGパイプラインの処理フロー — 文書のチャンク分割からベクトル検索、回答生成までの5ステップ
検索精度の改善サイクル
ナレッジベースを構築したら終わりではありません。精度改善は継続的なプロセスです。
ステップ1: テストクエリの準備。 実際の従業員が質問しそうなクエリを20〜30件用意します。正解(期待される回答)も合わせて定義します。
ステップ2: 検索結果の評価。 各クエリに対してDifyが返すチャンクを確認し、「正しいチャンクが上位に来ているか」を評価します。Difyのデバッグ機能でチャンクの検索結果とスコアを確認できます。
ステップ3: チューニング。 精度が低いクエリについて、チャンクサイズの調整、検索方式の変更(ベクトル検索 → ハイブリッド検索)、ドキュメントの前処理改善を行います。
このサイクルを2〜3回転すると、大半のクエリで実用的な精度に到達します。
料金・デプロイ・競合比較 — 導入判断に必要な情報
料金プランの選び方
Difyのクラウド版は4段階のプランを提供しています。
Sandbox(無料): メッセージ200件(累計)、アプリ5個。個人の検証用。チームでの利用やRAGの本格検証には不足します。
Professional(月額$59): メッセージ5,000件/月、アプリ50個、ナレッジベース文書500件。小規模チーム(3名まで)での本格運用に適しています。ブランディングカスタマイズにも対応します。
Team(月額$159): メッセージ10,000件/月、アプリ200個、チームメンバー50名。部門単位での運用に適した中間プランです。
Enterprise(要問合せ): SSO認証、マルチワークスペース、高可用性サポート付き。カカクコムのような全社導入向けです。
セルフホスト版はCommunity Edition(無料)ですべてのコア機能が使えます。 推奨スペックは8 CPUコア、16GB RAM。Docker Composeで30分程度でセットアップ可能です。データを社内に閉じたい場合やカスタマイズが必要な場合に選択します。ただし、運用・監視・バックアップは自社責任となります。
ポジショニング比較
Difyの競合であるn8nとFlowiseは、それぞれ異なる強みを持っています。
Difyの強み: UI使いやすさとRAG統合で圧倒的。非エンジニアが最も導入しやすい。Difyの弱み: 外部連携がAI関連に限定。Slack通知やCRM連携など業務ツールとの統合はAPIを自前で実装する必要があります。
n8nの強み: 600以上の外部連携。既存業務ツールとの統合が必要な場合はn8nが有力。n8nの弱み: RAGの組み込みがなく、自前構築が必要。UIもDifyよりエンジニア寄りです。
Flowise: チャットボット特化でRAG対応も良好。ただしエージェント設計機能やワークフローの柔軟性ではDifyに劣ります。
使い分けの指針: 「社内ナレッジ活用・AIエージェント構築が主目的」ならDify、「既存業務ツールとのAPI連携が主目的」ならn8n、「シンプルなRAGチャットボットを素早く作りたい」ならFlowiseです。n8nの設計パターンについてはn8n × AIエージェントの3つの設計パターンで詳しく解説しています。
Dify × n8n × Zapier:実務で見えた使い分けの本質
私たちが複数の導入プロジェクトで得た結論として、「Difyは頭脳、n8nは手足、Zapierは神経系」という比喩が最もしっくりきます。
Difyが最適な領域は「AIが考える」業務です。 ナレッジベースを参照した質問応答、文書の分析・要約、エージェントによる自律的な調査など、LLMの推論能力が価値の中心にある業務ではDifyが圧倒的に強い。RAGの組み込み、プロンプトの版管理、推論戦略の切り替えがUI上で完結するため、非エンジニアのチームでも「AIの考え方」を調整できます。
n8nが最適な領域は「システム間をつなぐ」業務です。 Slack通知、Google Sheets連携、CRMのデータ更新など、複数のSaaSを横断するワークフローではn8nの600以上のインテグレーションが活きます。AIノードも搭載しているため「途中でLLMに判断させる」ことも可能ですが、RAGの構築やエージェントの設計はDifyの方が圧倒的に楽です。
Zapierが最適な領域は「トリガー起点の軽量自動化」です。 「メールが届いたらSlackに転送」「フォーム回答をスプレッドシートに記録」のような、イベント駆動型のシンプルな連携はZapierが最も素早く構築できます。ただし、AIエージェントの構築やRAGの統合にはZapierは不向きです。
実務上のベストプラクティスは「組み合わせ」です。 例えば、Difyで構築したFAQボットのAPIをn8nから呼び出し、回答結果をSlackに通知する。あるいは、ZapierでGoogle Formの回答を受け取り、Webhookを経由してDifyのワークフローを起動する。このように、各ツールの得意領域を組み合わせることで、単一ツールでは実現できない業務自動化が可能になります。
ツール選定で迷ったときの判断基準
「この業務の価値の中心はどこか?」と問いかけてください。AIの推論が中心なら Dify、システム連携が中心なら n8n、イベント通知が中心なら Zapier。複数の要素が絡む場合は、APIで連携させる前提で「各領域の最適ツール」を組み合わせます。
知っておくべき制限事項
Difyの制限事項を事前に把握しておくことで、導入後のトラブルを回避できます。
- マルチエージェント非対応: 複数のエージェントが協調して動作するシステムはネイティブには構築できません。単一エージェントの範囲で設計するか、API連携で外部から制御する必要があります
- モデルファインチューニング非対応: Dify内でモデルのファインチューニングはできません。プロンプトエンジニアリングとRAGで精度を上げるアプローチが前提です
- データ構造の深度制限: ワークフロー内のデータ構造は1レベル深度のみ対応。ネストしたJSONの処理にはコード実行ノードでの加工が必要です
- ベンダーロックインリスク: AIワークフローのエクスポート標準が存在しないため、他プラットフォームへの移行時にワークフローロジックの再実装が必要です
本番運用のガードレール設計
Difyでエージェントを構築した後、本番運用で最も重要なのは暴走防止とコスト管理です。
エージェント暴走の防止
エージェントは自律的に行動するため、想定外のループや過剰なAPI呼び出しが発生するリスクがあります。対策は3層で設計します。
第1層: イテレーション上限の設定。 エージェントの推論ループ回数に上限を設けます。Difyのエージェント設定画面で最大イテレーション数を指定でき、上限に達した時点で「最善の回答」を返して終了します。初期値は5〜10回が安全な範囲です。
第2層: トークン/コスト上限。 1回のリクエストあたりのトークン消費量に上限を設けます。特にGPT-4やClaude 3.5 Opusのような高コストモデルを使う場合、1リクエストが数ドルに達することもあります。Difyのモニタリング機能でトークン消費を可視化し、閾値を超えた場合にアラートを出す運用を組みます。
第3層: 出力のポストフィルタリング。 エージェントの出力に対して、機密情報の漏洩チェックやコンテンツポリシー違反の検出を行います。Difyのワークフローの末尾に「出力チェック」ノードを追加し、NGワードの検出やフォーマット検証を自動化できます。
3段階成長モデル
Difyの導入は段階的に進めるのが成功の鍵です。
第1段階(1〜2週間): チャットボット。社内FAQなどリスクの低いユースケースから始め、RAGの精度検証と社内の利用定着を図ります。
第2段階(1〜2ヶ月): ワークフロー。定型業務の自動化に進みます。HITLノードで人間の承認を挟みながら、自動化の範囲を段階的に広げます。
第3段階(3ヶ月〜): エージェント。自律判断が必要な業務にエージェントを導入します。ReActの推論ログを定期的にレビューし、判断品質を監視します。
この順序で進めることで、組織全体のAIリテラシーが自然に向上し、エージェント導入時の抵抗感も低減します。カカクコムが950アプリを実現できたのも、全社展開の前にPoCフェーズで成功体験を積み上げたからです。
私たちの経験では、第1段階のチャットボットで「AIが社内文書を正しく理解して回答する」体験を全社員に提供することが、その後の展開速度を決定的に左右します。 逆に、最初からエージェントを導入しようとすると、出力の不安定さへの不信感が組織全体に広がり、第2段階以降の推進が極端に難しくなります。最初の成功体験の設計に最も時間をかけるべきです。
まとめ
Difyは「使い方」を覚えるだけのツールではありません。業務課題に対して適切なアプリケーションタイプを選び、適切な設計パターンで実装することで、初めて実用的なAIエージェントが完成します。
本記事で紹介した設計判断の要点を振り返ります。
- アプリケーションタイプの選択: 手順確定ならワークフロー、単純応答ならチャットボット、自律判断が必要ならエージェント
- RAGの精度: 1テーマ1ナレッジベース、PDF→Markdown変換、ハイブリッド検索で94%を目指す
- エージェント戦略: 透明性が必要ならReAct、速度優先ならFunction Calling
- HITLの配置: 導入初期は全件承認、データ蓄積後に段階的自動化
- ガードレール: イテレーション上限、コスト上限、出力フィルタの3層防御
まずはSandbox(無料)で設計判断ツリーに沿ったプロトタイプを1つ作り、3段階成長モデルで本番運用まで進めてみてください。
Agenticベースでは、Difyを含むノーコードAIプラットフォームの選定支援から、エージェント設計・RAG構築・本番運用体制の整備まで対応しています。 お問い合わせはこちら →
Footnotes

この記事の著者
Agentic Base 編集部
AIエージェントとWebメディア運用の知見を活かし、実践的なナレッジを発信しています。